基于《Wireshark网络分析就这么简单》一书对wireshark的学习
Life is tough,but Wireshark makes it easy
Wireshark网络分析就这么简单.(z-lib.org).pdf
第一章:初试锋芒
Wireshark抓包
这里因为没有相同的电脑配置条件,所以无法模拟书上测试连接的过程,只能演示如何抓包
选择本机物理网卡
双击该网卡选项就会自动对本机进行流量抓包
Wireshark界面布局
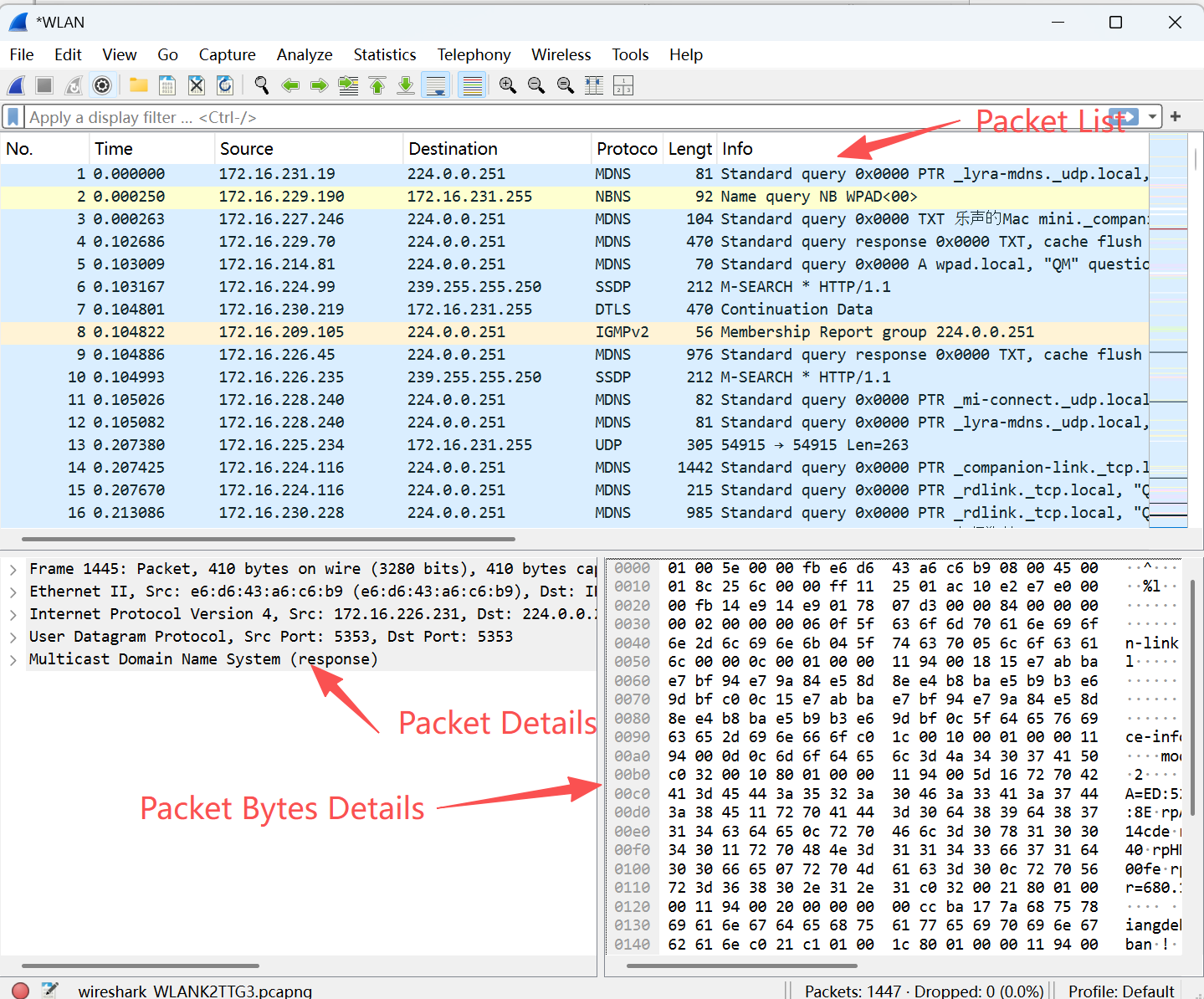
最上面是Packet List窗口,它列出了所有网络包,在Packet List中选定的网络包会详细地显示在中间的Packet Details窗口,最底下是Packet Bytes Details窗口,我们一般不会用到它
点击红色方块按钮来停止,或者点击鲨鱼鳍按钮来继续抓包
从一道面试题开始说起
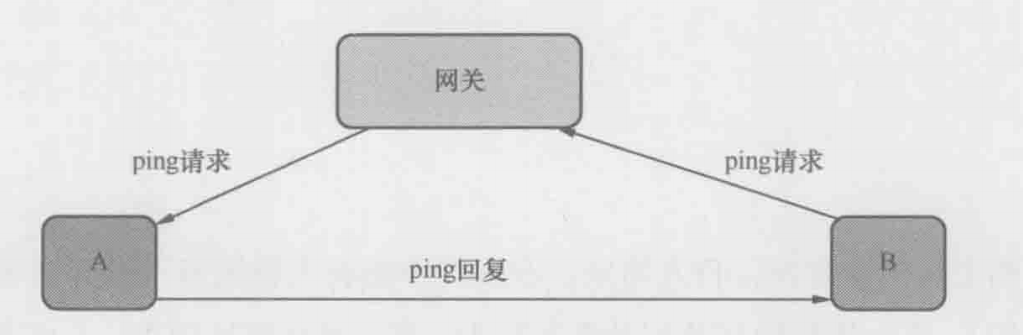
问题:两台服务器A和B的网络配置如下,B的子网掩码本应该是255.255.255.0,被不小心配成了255.255.255.254,它们还能正常通信吗?
服务器A:
IP地址:192.168.26.129
子网掩码:255.255.255.0
默认网关:192.168.26.2
服务器B:
IP地址:192.168.26.3
子网掩码:255.255.255.224
默认网关:192.168.26.2

用服务器B去ping服务器A,发现是通的
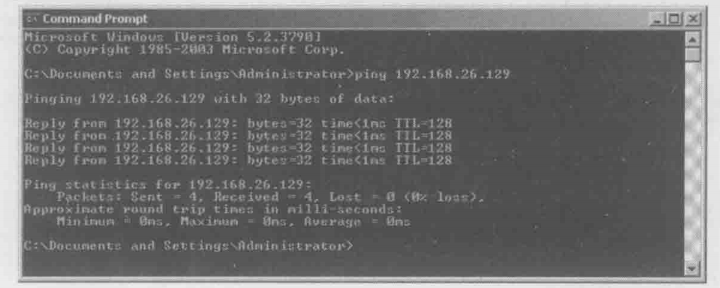
现在对服务器B ping服务器A的过程抓包
现在来看看每个包都做了些什么
1号包

服务器B通过ARP广播查询默认网关192.168.26.2的MAC地址
为什么我ping的是服务器A的IP,B却去查询默认网关的MAC地址呢?
这是因为B根据自己的子网掩码计算出A属于不同子网,跨子网通信需要默认网关的转发,而要和默认网关通信,就需要获得其MAC地址
2号包

MAC地址前三位的含义
默认网关192.168.26.2向B回复了自己的MAC地址,为什么这些MAC地址的开头明明是“00:50:56”或者“00:0c:29”,Wireshark上显示出来却都是“Vmware”?
这是因为MAC地址的前3个字节标识厂商,而00:50:56和00:0c:29都被分配给了Vmware公司,这是全球统一的标准,所以Wireshark干脆显示出厂商名了
3号包

B发出ping包,指定Destination IP为A,即192.168.26.129,但Destination MAC却是默认网关的 00:50:56:e7:2f:88,这表名B希望默认网关把包转发给A
4号包

B收到了A发出的ARP广播,这个广播查询的是B的MAC地址,这是因为在A看来,B属于相同子网,同子网通信无需默认网关的参与,只需要通过ARP获得对方的MAC地址就行了,这个包也表名默认网关成功地把B发出的ping请求转发给A了,否则A就不会无缘无故尝试和B通信
子网掩码不对称导致的通信问题
在分析服务器B的网络包过程中发现ping服务器A的IP,B却去查询默认网关的MAC地址
这是因为B根据自己的子网掩码计算出A属于不同子网
(详见https://www.yuque.com/fragrantveget/iqit07/ivvc4vsn9zym0mzq?singleDoc# 《(未完)IP地址与子网掩码》中如何确定两个IP是否在同一子网?)
而A看来B属于相同子网,无需默认网关的参与
这是为什么?
首先看先看各自的网络配置
服务器A:
IP:192.168.26.129
子网掩码:255.255.255.0 → 即 /24
网络地址 = 192.168.26.129 & 255.255.255.0 = 192.168.26.0
所以 A 认为:自己所在的子网是 192.168.26.0/24(可用的主机数:2^8-2=254 范围:192.168.26.1 ~ 192.168.26.254)
服务器B:
IP:192.168.26.3
子网掩码:255.255.255.224 → 即 /27
网络地址 = 192.168.26.3 & 255.255.255.224 = 192.168.26.0
所以 B 认为:自己所在的子网是 192.168.26.0/27(可用的主机数:2^5-2=30 范围:192.168.26.1 ~ 192.168.26.30)
再互相判断对方是否在同一子网
A 判断 B 是否在同一子网:
A 的子网掩码是 /24,所以它用 192.168.26.3 & 255.255.255.0 = 192.168.26.0
A 自己的网络地址也是 192.168.26.0
所以 A 认为 B 在同一子网
B 判断 A 是否在同一子网:
B 的子网掩码是 /27,所以它用 192.168.26.129 & 255.255.255.224
255.255.255.224 的二进制是:11111111.11111111.11111111.11100000
192.168.26.129 的二进制最后 8 位是:10000001
按位与后得到:10000000 → 即十进制 128
所以网络地址 = 192.168.26.128
B 自己的网络地址是 192.168.26.0(因为 3 & 224 = 0)
所以 B 认为 A 不在同一子网(因为 192.168.26.128 ≠ 192.168.26.0)
三、结论
A 使用 /24 掩码,看到整个 192.168.26.0~255 都是本地网络,因此认为 B 在本地。
B 使用 /27 掩码,只认为 192.168.26.0~30 是本地网络,而 A 的 IP(129)落在 192.168.26.128/27 子网中,不在自己的子网内。
因此:
B 要发包给 A 时,会把数据包交给默认网关(192.168.26.2)转发。
A 要发包给 B 时,会直接通过 ARP 广播尝试获取 B 的 MAC 地址(因为认为是本地)。
5号包

B回复了A的ARP请求,把自己的MAC地址告诉A,这说明B在执行ARP回复时并不考虑子网,虽然ARP请求来自其他子网的IP,但也照样回复
6号包

B终于收到了A的ping回复,从MAC地址 00:0c:29:0c:22:10 可以看出,这个包是从A直接过来的,而不是通过默认网关的转发
ARP的通讯逻辑
为什么A、B服务器属于不同子网,但是回复ARP请求时却不需要通过默认网关转发呢
通信过程
B先把ping请求交给默认网关,默认网关在转发给A,而A收到请求后直接把ping回复给B
小试牛刀:一个简单的应用实例
客户不小心重启了服务器A,然后它就再也无法和服务器B通信了
问题听起来并不复杂,考虑到起因是服务器A重启,所以收集了它的网络配置
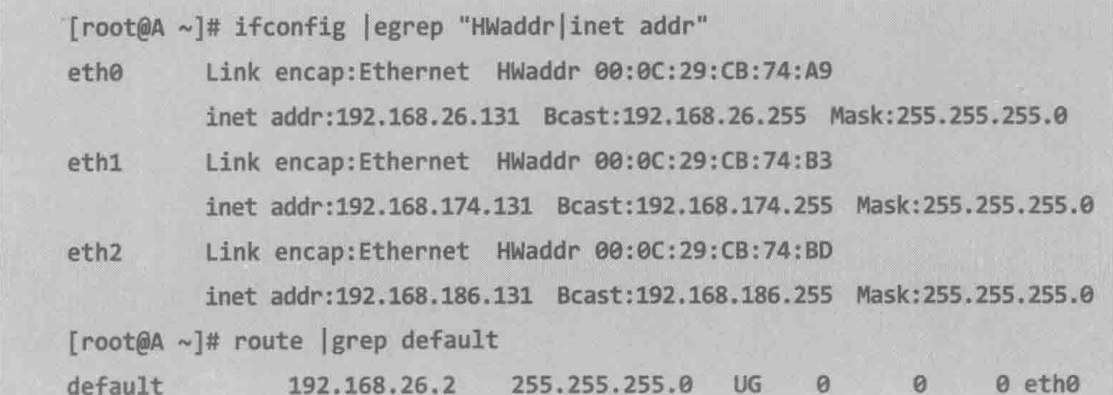
这里详细解释下命令:
ifconfig | egrep “HWaddr|inet addr”
的含义
1.ifconfig
会列出所有网络接口(如eth0、wlan0、lo等)的详细信息,包括IP地址、MAC地址、子网掩码、状态等
2.|(管道)
将前一个命令的输出结果作为输入传递给后面的命令,在这行命令里面是将ifconfig的输出结果作为输入传递给egrep命令
3.egrep
egrep 是 grep -e的别名,支持使用扩展正则表达式(extended regular expressions)
4.”HWaddr|inet addr”
这是一个正则表达式,其中:
HWaddr通常出现在以太网接口行中,表示硬件地址(即MAC地址)
inet addr在较旧版本的ifconfig输出中表示IPv4地址(新版本可能只写成inet)
| 表示或
所以,这行命令的含义是从 ifconfig 命令的输出中筛选出包含 “HWaddr” 或 “inet addr” 的行
服务器A拥有多个IP地址,而服务器B的网络配置则简单很多,只有一个IP地址 192.168.182.131,子网掩码也是255.255.255.0
一般情况下,像A这类多IP的服务器是这样配路由的:
假如自身有一个IP和对方在同一子网,就从这个IP直接发包给对方,假如没有一个IP和对方在同一子网,就走默认网关
在这个环境中,A的3个IP显然都与B属于不同子网,那就应该走默认网关了
会不会是A和默认网关的通信出问题了呢,从A上ping了一下网关,结果却是通的
分别在eth0、eth1和eth2上抓了包,最先查看的是连接默认网关的eth0,出乎意料的是,上面竟然一个网络包都没有,而在eth1上抓的包确实下图的表现:
A正通过ARP广播查找B(192.168.182.131)的MAC地址,试图绕过默认网关直接与B进行通信
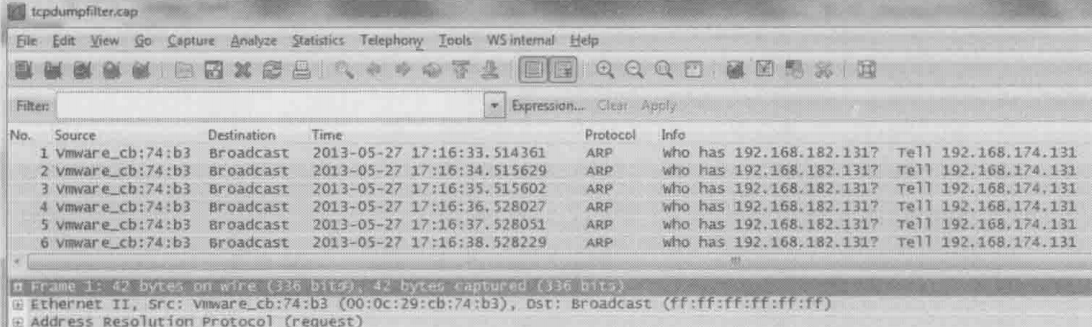
这说明A上存在一项符合192.168.182.131的路由,促使A通过eth1直接与B通信
逐项检查路由表,果然发现有这么一项

因为192.168.182.131属于192.168.182.0/255.255.255.0,所以就会走这条路由
即使在同一个子网内,如果两个主机在不同的 VLAN 中,它们也无法直接通信,由于 VLAN 隔离了广播域,所以这些ARP请求根本到不了B
客户删除了这条路由后两台服务器的通信也随之恢复
Excel文件的保存过程
原来的文件被重命名成一个临时文件,而创建的拥有源文件所有信息临时文件又被重命名成源文件的名字,然后再删除生成的临时文件
你一定会喜欢的技巧
一、抓包
1.只抓包头
一般能抓到的包的最大长度为1514个字节,启用了巨型帧(Jumbo Frame)之后可达到9000字节以上,而大多数我们只需要IP头或者TCP头就足够分析了
2.只抓必要的包
服务器上的网络连接可能非常多,而我们只需要其中的一小部分
Wireshark的Capture Flite 可以在抓包时过滤掉不需要的包
https://zhuanlan.zhihu.com/p/1935743651344000032 Wireshark 过滤语法太多记不住?这一篇直接全汇总!
二、个性化设置
1.调整时间格式
经常需要参照服务器上的日志实践,所以把Wireshark的实践调成跟服务器一样的格式
单机Wireshark的 view –> time display format –> date and time of day
2.自定义颜色
可以通过view –> coloring rules 来设置颜色
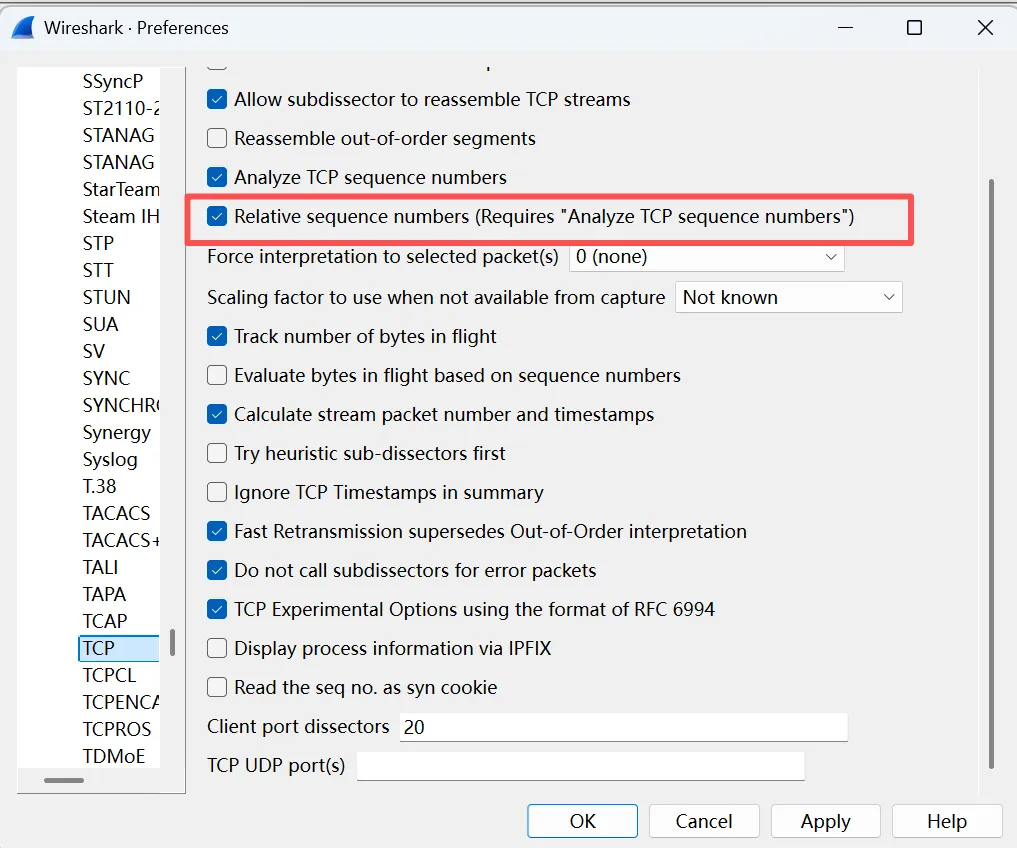
3.Relative sequence numbers
更多的设置可以在 edit –> preferences 窗口中完成。假如经常要对 Sequence Number 做加减运算,不妨选中 Relative sequence numbers,这样会使Sequence number 看上去比实际小很多
4.统一时区
如果在其他时区的服务器上抓包,然后下载到自己的电脑上分析,最好把自己电脑的时区设成跟抓包的服务器一样
三、过滤
1.如果已知某个协议发生问题,可以用协议名称过滤一下
用协议过滤时务必考虑到协议间的依赖性
2.IP地址加port号时最常用的过滤方式
ip.addreq<IP地址>&&tcp.porteq<端口号>
Wireshark还提供了更快捷的方式:右键点击感兴趣的包,选择follow tcp/udp stream (选择tcp还是udp要视传输层协议而定)
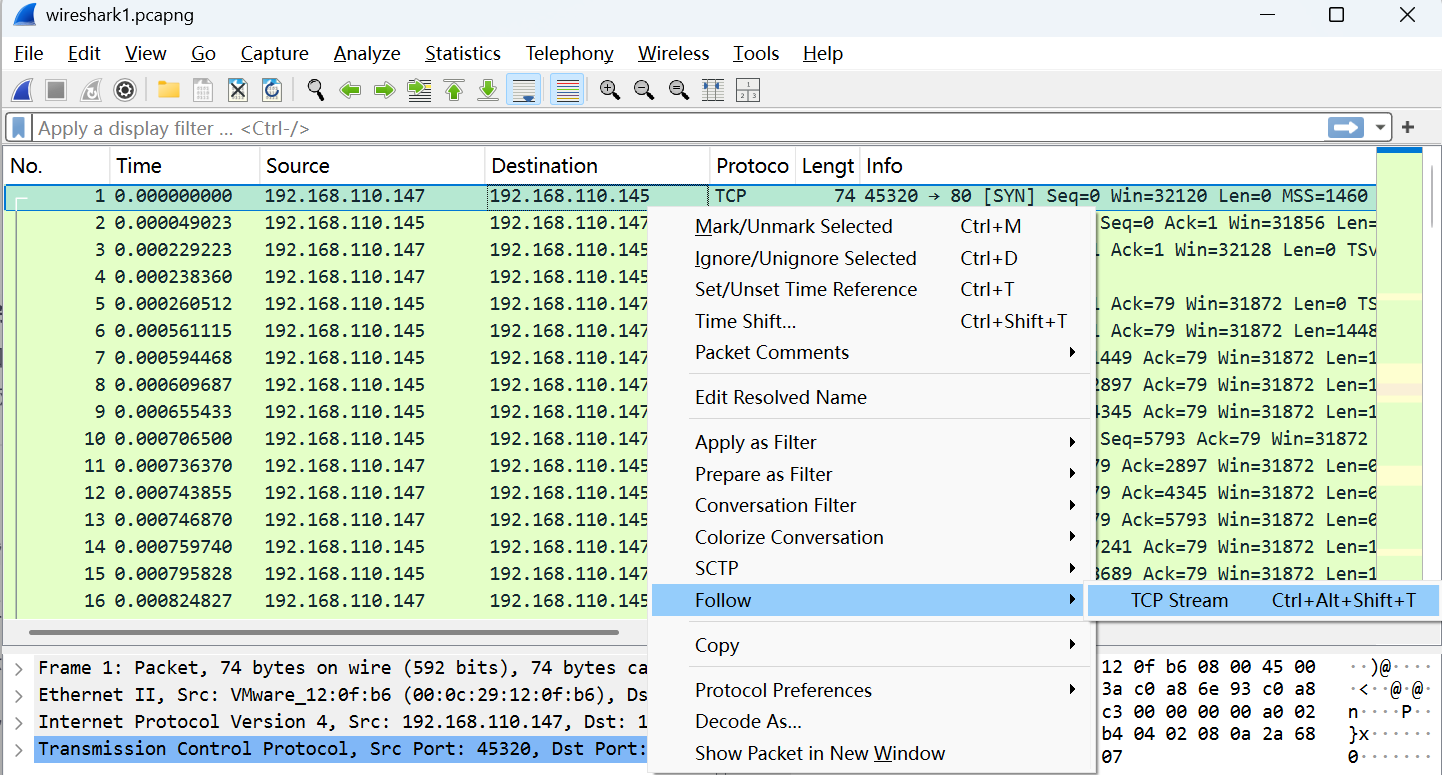
Wireshark是按照什么过滤出一个tcp/udp stream的?
两端的ip加port
单机Wireshark的statistics –> conversations,再点击tcp或者udp标签就可以看到左右的stream
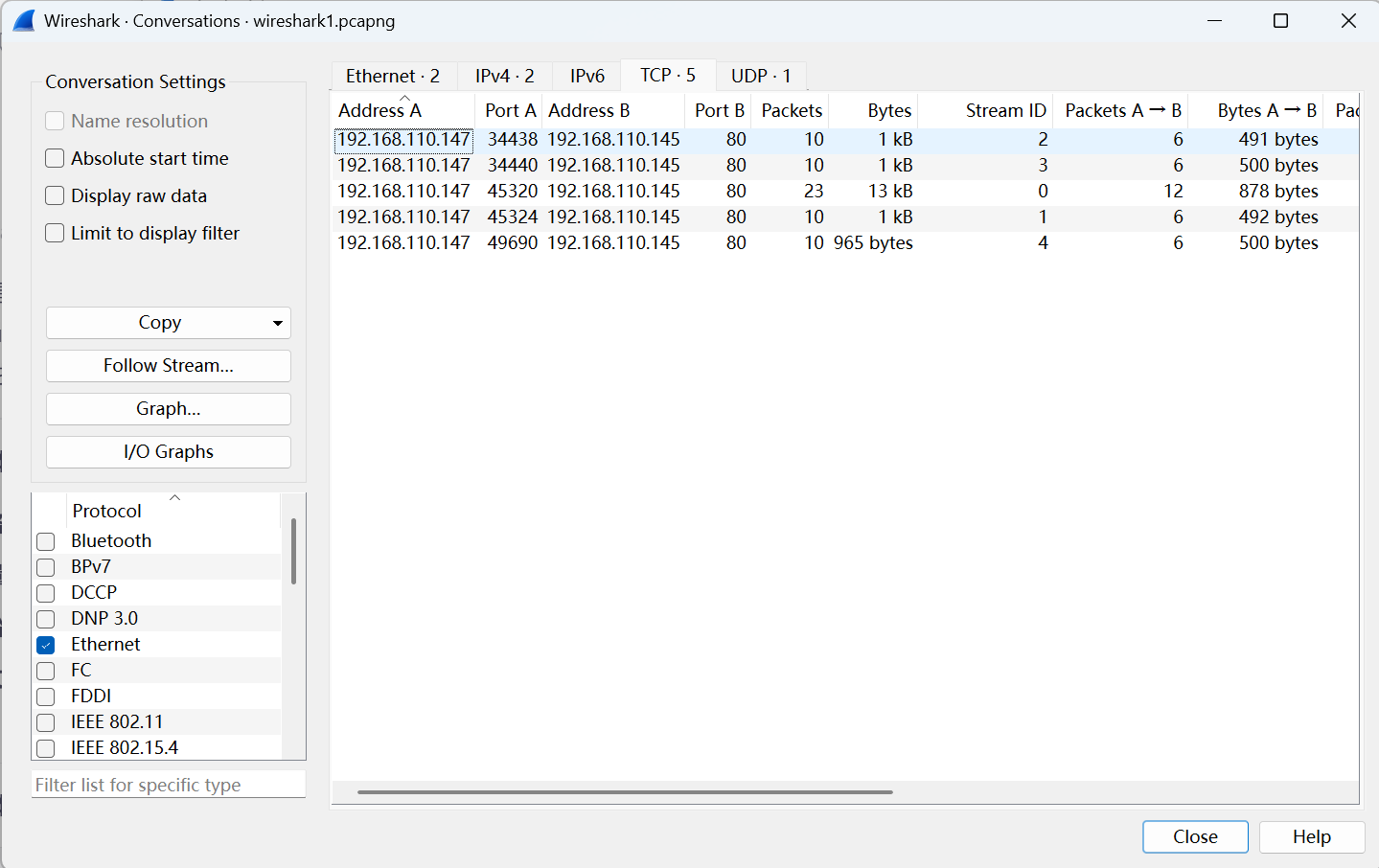
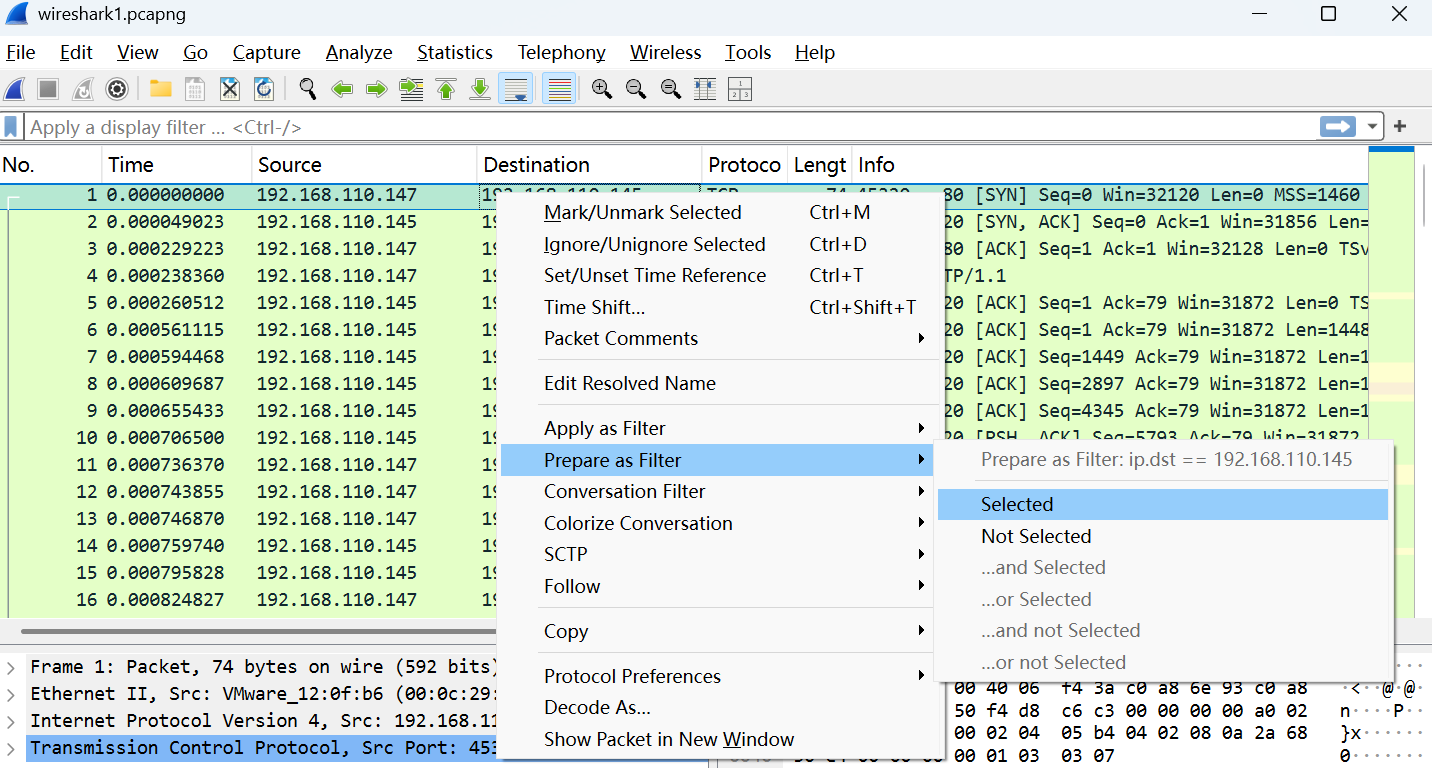
3.用鼠标帮助过滤
右键单机Wireshark上感兴趣的内容,然后选择prepare a filter –>selected,就会在filter框中自动生成过滤表达式
假如右键单击之后选择的不是prepare a filter,而是apply as filter –>selected,则该过滤表达式生成后还会自动执行
4.保存筛选后的网络包
我们可以把过滤后得到的网络包存在一个新的文件里,因为小文件更方便操作
单机Wireshark的file –>save as,选中displayed 单选按钮再保存,得到的新文件就是过滤后的部分
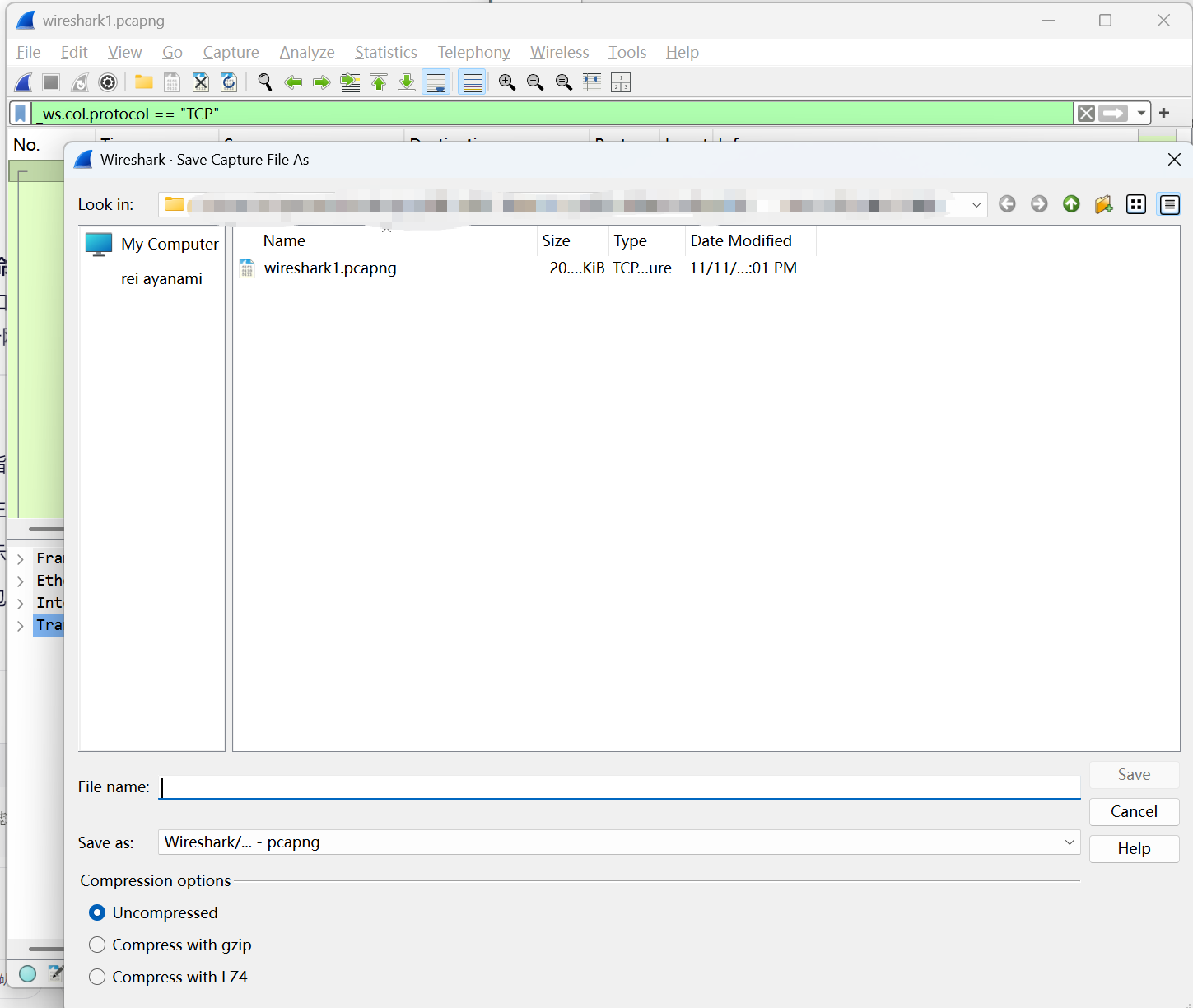
有时候会发现,保存后的文件在打开时会显示很多错误,这是因为过滤后得到的不再是一个完整的tcp stream
注意:有些Wireshark版本把这个功能移到了菜单file –> export sepcified packets 选项中
四、让Wireshark自动分析
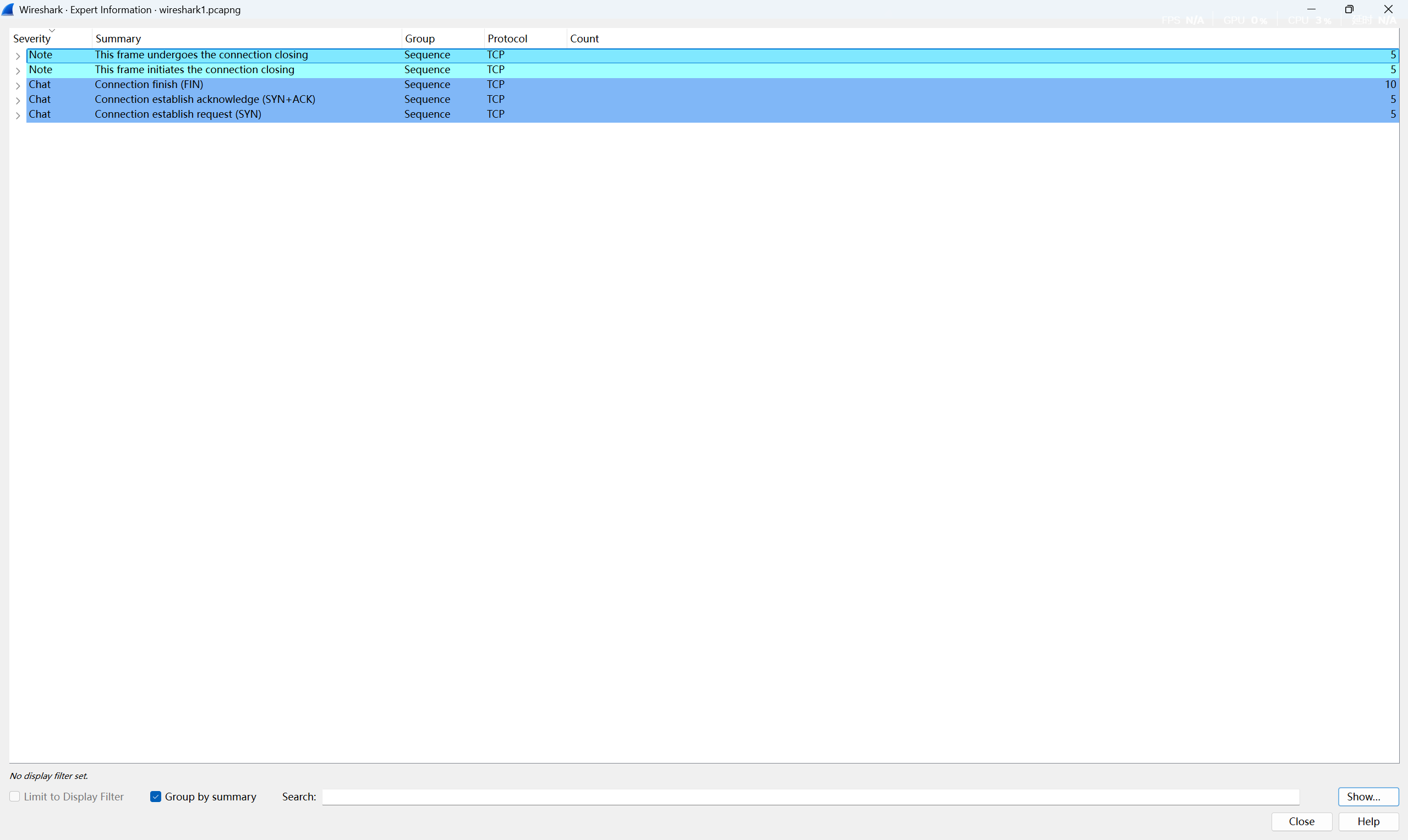
1.专业信息
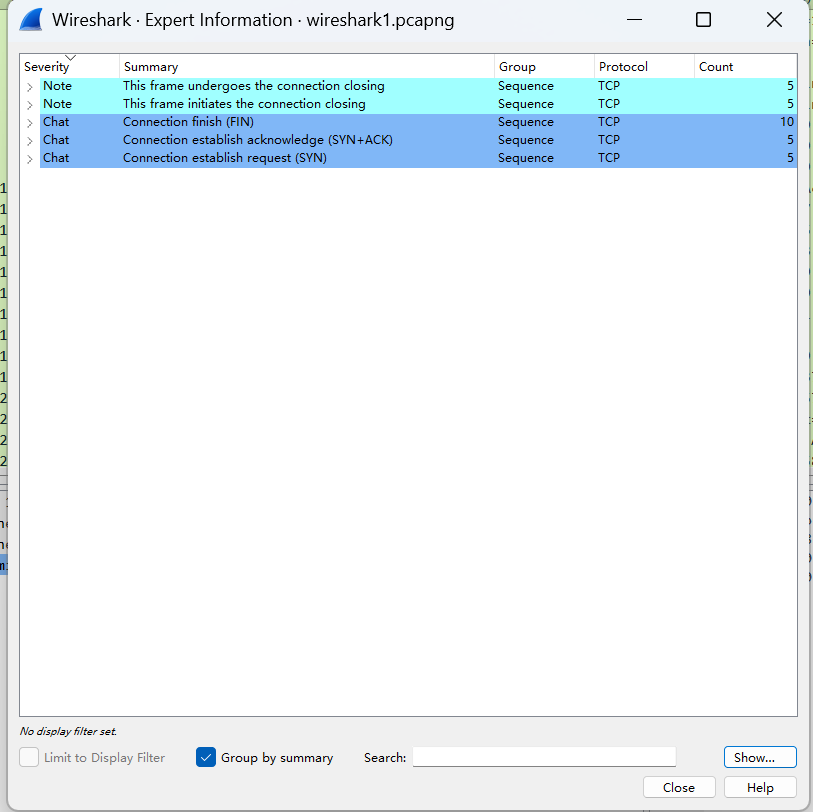
单机Wireshark的analyze –> expert information,就可以在不同标签下看到不同级别的提示信息
比如重传的统计、连接的建立和重置统计
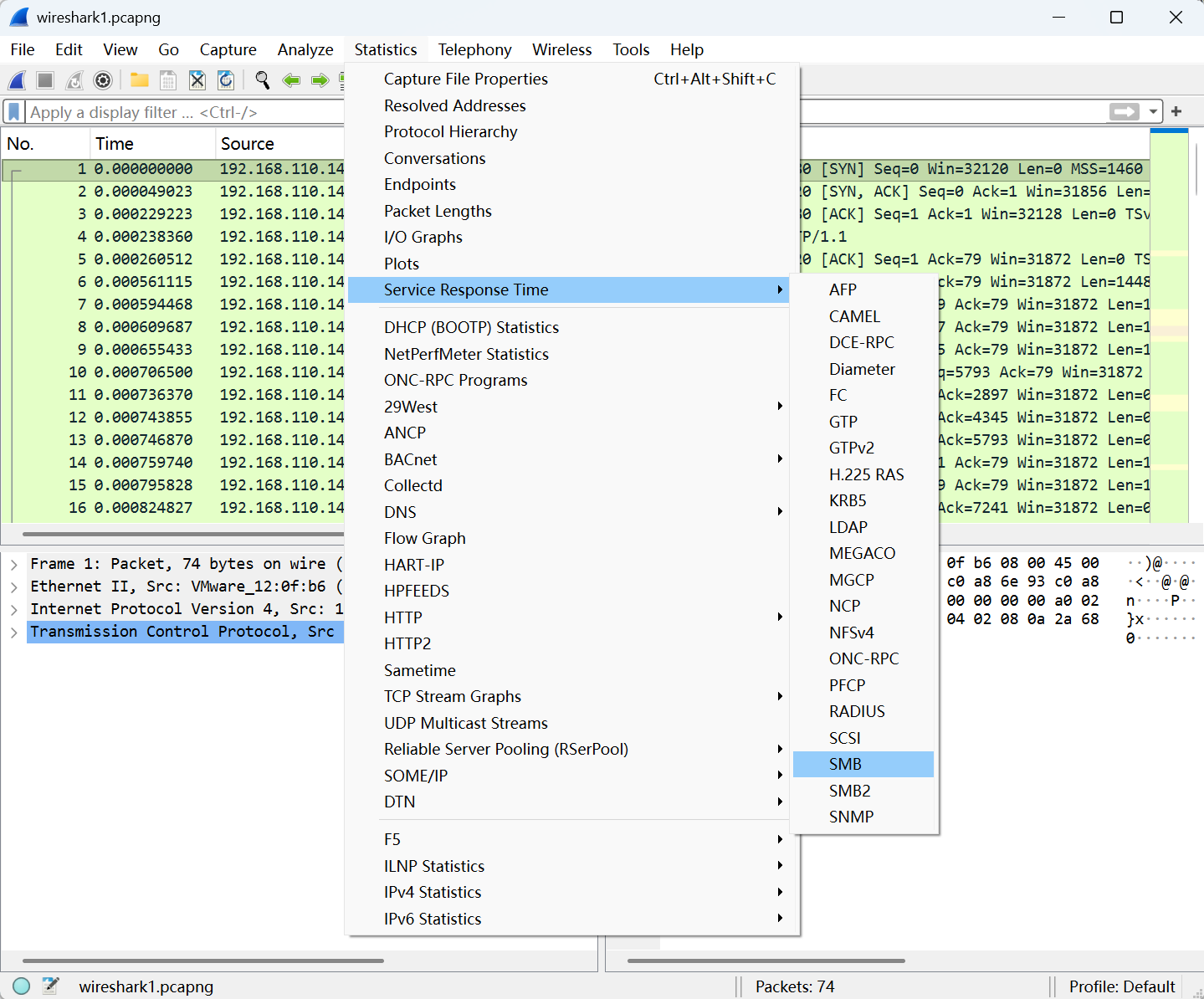
2.响应实践统计表
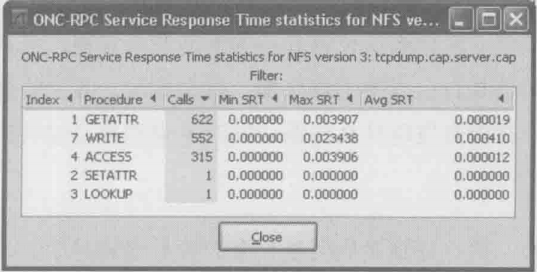
单机statistics –> service response time,再选定协议名称,可以得到响应实践的统计表,在衡量服务器性能时经常需要此统计结果
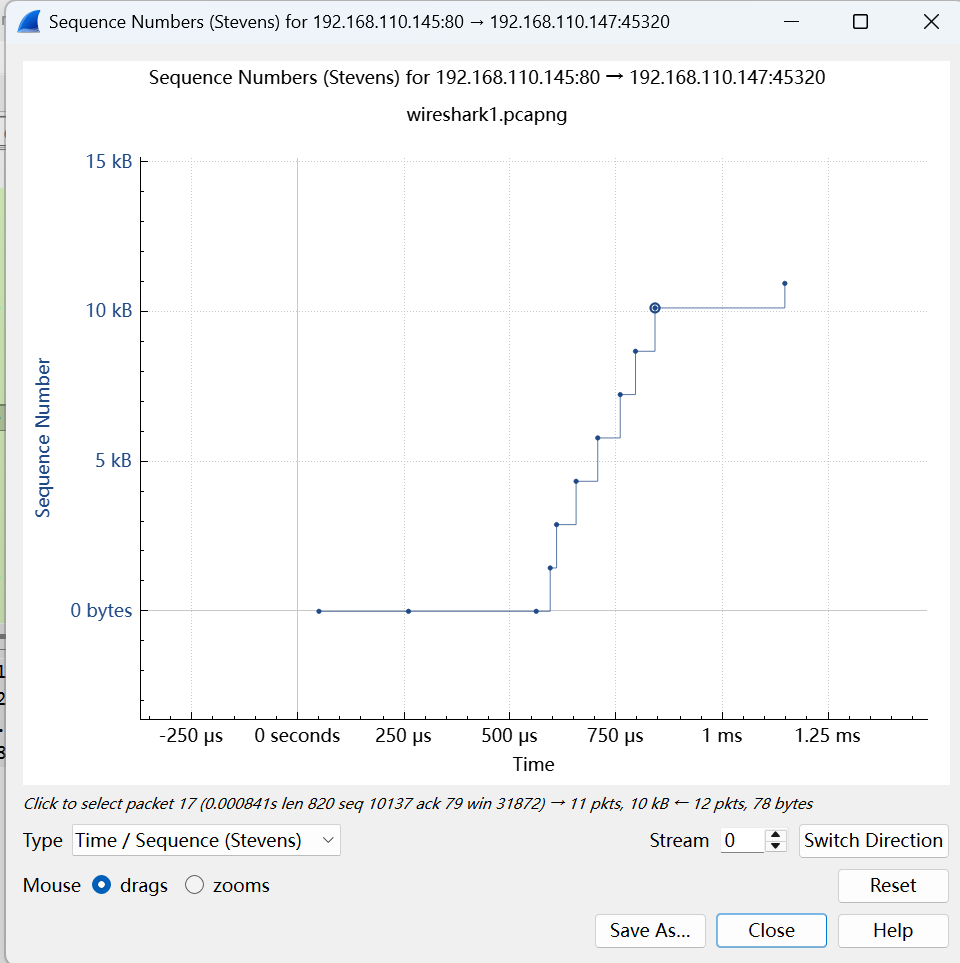
3.统计图生成
单机statistics –> tcp stream graph 可以生成几类统计图
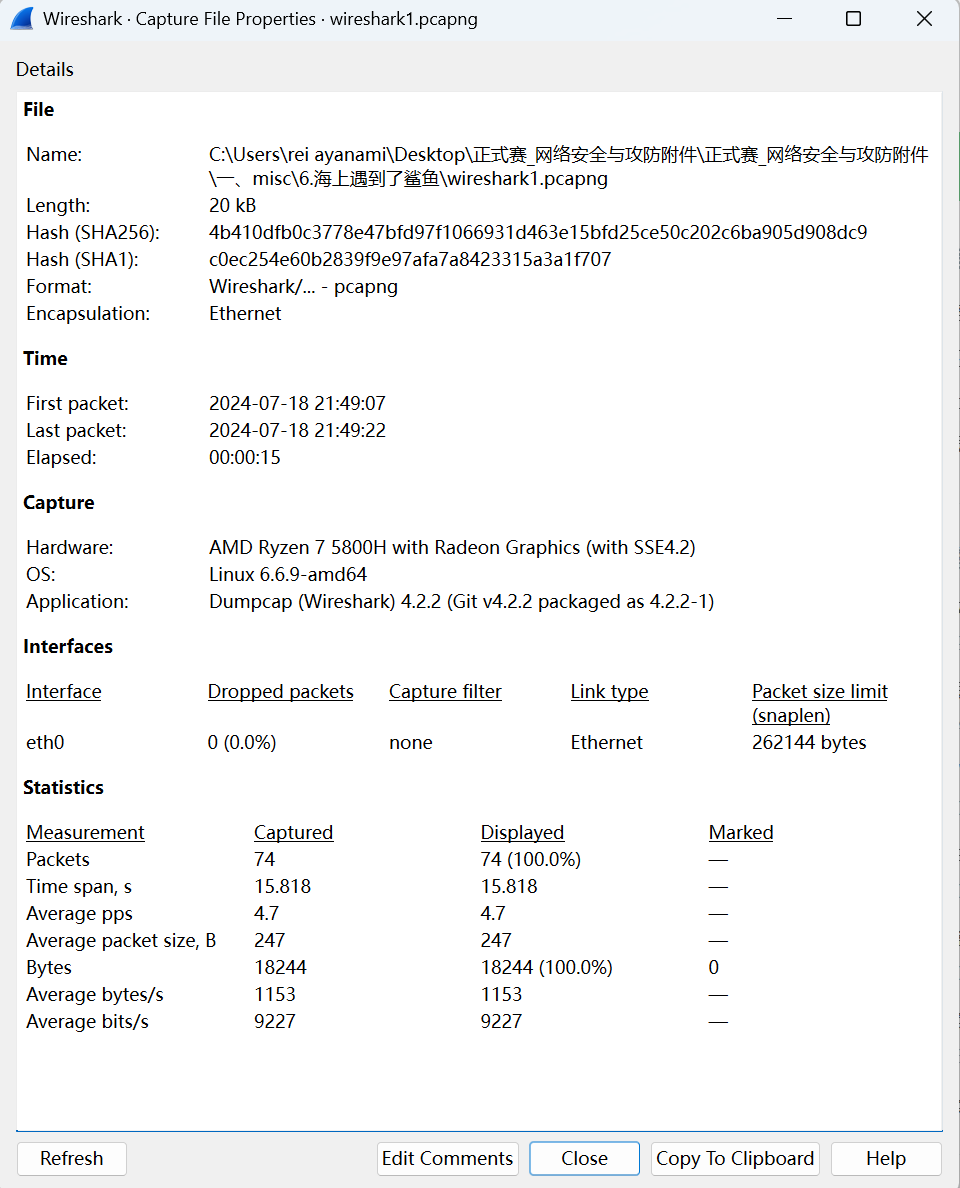
4.统计信息查看
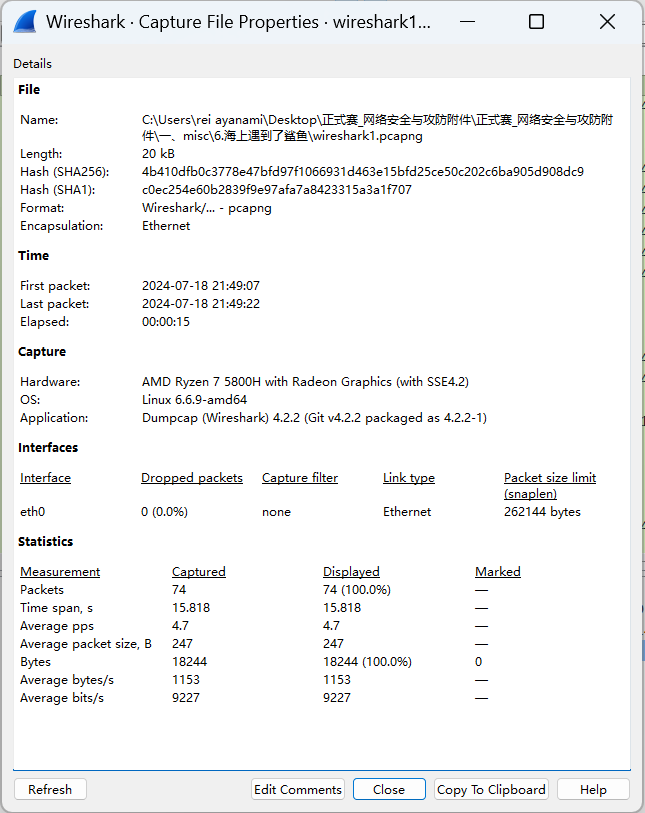
单机sattistics –> capture file properties 可以看到一些统计信息,比如平均流量等,这有助于我们推测负载情况
五、最容易上手的搜索功能
通过ctrl+f搜索关键字
第二章:庖丁解牛
NFS协议解析
NFS(Network File System)协议是太阳公司发明的网络上的文件传输系统
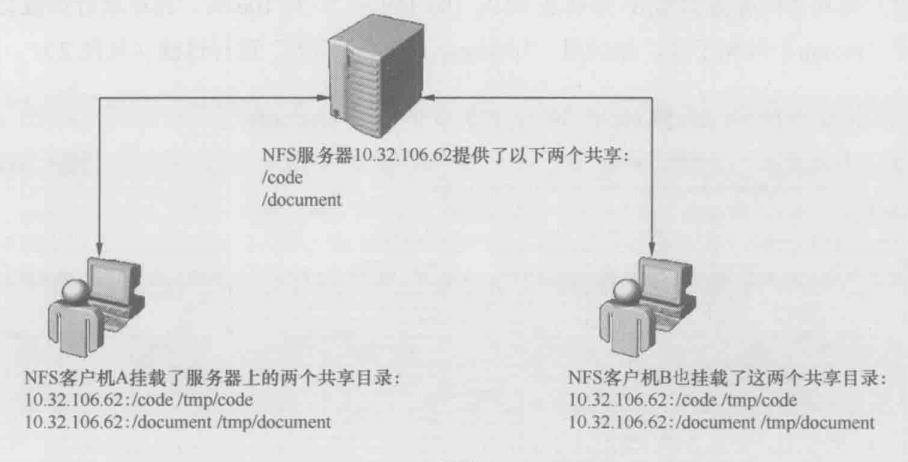
理论上NFS适用于任何操作系统,不过因为种种原因,一般只在linux/unix 环境存在
NFS挂载过程
下面将通过分析网络包解析NFS协议
NFS客户端的IP是10.32.106.159
文件服务器的IP是10.32.106.62
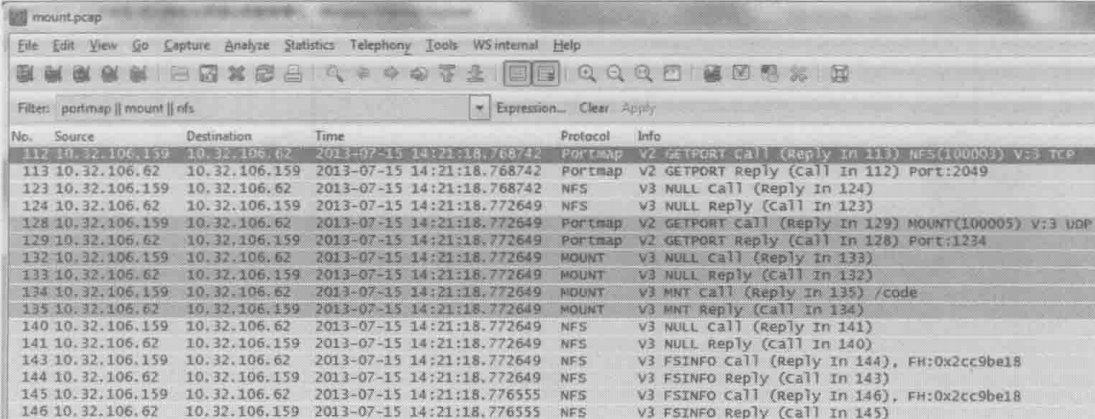
在运行挂载命令(mount)时抓了包,然后用“portmap||mount||nfs”进行过滤

注:
mount命令是linux/unix系统中用于挂载文件系统的命令,即将一个存储设备(如硬盘分区、USB 闪存盘、网络共享等)或虚拟文件系统连接到操作系统的目录树中的某个目录(称为“挂载点”),使得用户和程序可以像访问普通目录一样访问该设备上的数据
上图的命令即为将文件服务器 10.32.106.62:/code挂载到NFS客户端的/tmp/code文件夹中
上文中的过滤条件中 || 是wireshark的过滤逻辑操作符 or
与 为 &&/and
非 为 !/not
上图中info一栏可以看到,wireshark已经提供了详细的解析,这里还是翻译成更直白的对话
112和113号包

客户端:“我想连接你的NFS进程,应该用哪个端口呀?”
服务器:“我的NFS端口是2049”
123和124号包

客户端:“那我试一下NFS进程能否脸上”
服务器:“收到了,能连上”
128和129号包

客户端:“我想连接你的mount服务,应该用哪个端口呀?”
服务器:“我的mount的端口号是1234”
注:
在第一步中,客户端找到服务器的portmap进程,向它查询NFS进程的端口号,然后服务器的portmap进程回复了2049,portmap的功能是维护一张进程与端口号的对应关系表,而它自己的端口号111是众所周知的,其他进程都能找到它,这个角色类似很多公司的前台,她知道每个员工的分机号。
其实大多数文件服务器都会使用2049作为NFS端口号,所以即便不先咨询portmap,直接连2049端口也不会出现问题
第二步中客户端再次联系服务器的portmap,询问mount进程的端口号,与NFS不同的是,mount进程的端口号比较随机,所以这步询问是不能跳过的
第二步客户端尝试连接服务器的NFS进程,由此判断2049端口是否被防火墙拦截,还有NFS服务是否已经启动
132和133号包

客户端:“那我试一下mount进程是否能连上”
服务器:“收到了,能连上”
134和135号包
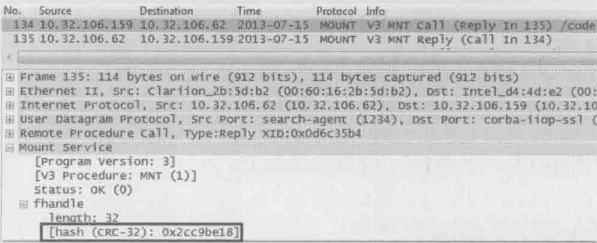
客户端:“我要挂载/code 共享目录”
服务器:“你的请求被批准了,以后请用 file handle 0x2cc9be18 来访问目录”
注:
第三步客户端尝试连接服务器的mount进程,由此判断1234端口是否被防火墙拦截,还有mount进程是否已经启动
第四步真正挂载了/code目录,挂载成功后,服务器把该目录的 file handle 告诉客户端(要点开详细信息才能看到 file handle)
140和141号包

客户端:“我试一下NFS进程能否连上”
服务器:“收到了,能连上”
143和144号包

客户端:“我想看看这个文件系统的属性”
服务器:“给,都在这里”
145和146号包

客户端:“我想看看这个文件系统的属性”
服务器:“给,都在这里”
以上便是NFS挂载的全过程,细节之处很多,所以在没有wireshark的情况下很难排错,经常不得不盲目地检查每一个环节
用上wireshark后就可以很有针对性地排查了
注:
第五步在作者看来没有必要,因为之前已经试连过NFS了,再测试一次有何意义?(检测NFS连接是否稳定?)作者猜测是开发人员不小心重复调用了同一函数,但因为没有抓包,所以测试人员也没有发现这个问题
第七步又是重复操作,更加怀疑是开发人员的疏忽,这个例子也说明了wireshark再辅助开发中的作用
NFS权限控制机制
NFS在安全方面的机制包括对客户端的访问控制和对用户的权限控制
NFS对客户端的访问控制是通过IP地址实现的,创建共享目录时可以指定哪些IP允许读写,哪些IP只允许读,还有哪些IP连挂载都不允许
虽然配置不难,但这方面出的问题往往很诡异,没有wireshark是几乎无法排查的
NFS的用户权限也经常让人困惑,比如客户端A上的用户admin 在/code 目录里新建一个文件,该文件的owner正常显示为admin,但是在客户端B上查看该文件是,owner却变成nasadmin
客户端A

客户端B

查看用户admin在创建/tmp/code/abc.txt 时的包
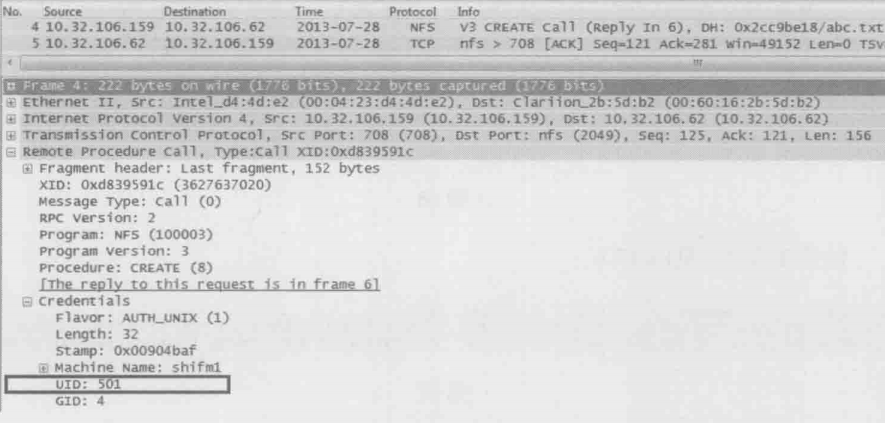
由上图的Credentials(身份凭证)信息可知,用户在创建文件时并没有使用admin这个用户名,而是用了admin的UID 501 来代表自己的身份(用户名与UID 的对应关系时由客户端的/etc/passwd 决定的),也就是说NFS协议是只认UID不认用户名的,当admin通过客户端A创建了一个文件,其UID 501 就会被写到文件里,称为owner信息
而当客户端B上的用户查看该文件属性是,看到的其实也是UID 501,但是因为客户端B上的/ etc/passwd 文件和客户端A上的不一样,其UID 501对应的用户名叫nasadmin,所以文件的owner就显示为nasadmin了。同样道理,当客户端B上的用户nasadmin在共享墓库上新建一个文件是,客户端A上的用户看到的文件owner就会变成admin。为了防止这类问题,建议用户名和UID的关系在每台客户端上都保持一致
NFS共享文件的读写过程
弄清楚了NFS的安全机制后,我们再来看看读写过程
读过程
下图展示了读取文件abc.txt 的过程

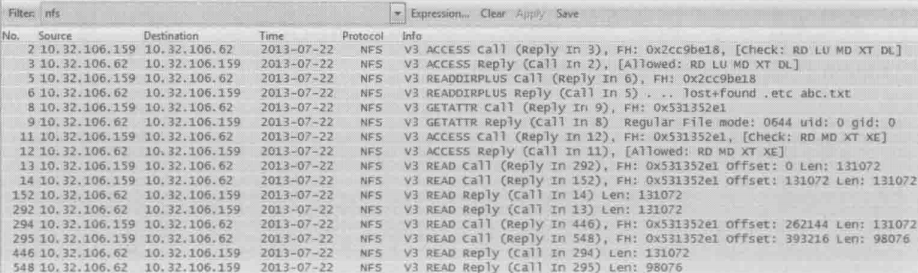
2和3号包

客户端:“我可以进入0x2cc9be18(也就是/code 的 file handle)吗?”
服务器:“你的请求被接受了,进来吧”
5和6号包

客户端:“我想看看这个目录里的文件及其 file handle”
服务器:“文件名及file handle 的信息在这里,其中abc.txt 的file handle 是 0x531352e1”
注:
这个file handle 也需要从包的详细信息里才能看到,就如之前提到过的,NFS操作文件时使用的时file handle,所以要先通过文件名找到其 file handle,而不是直接读其文件名。如果一个目录里文件数量巨大,获取file handle 可能就会比较费时,所以建议不要在一个目录里存放太多文件
8和9号包

客户端:“0x531352e1(也就是abc.txt)的文件属性是什么?”
服务器:“权限、uid、gid,文件大小等信息都给你”
11和12号包

客户端:“我可以打开0x531352e1(也就是abc.txt)吗?”
服务器:“你的请求被允许了,你有读、写、执行等权限”
13、14、152、292号包

客户端:“从0x531352e1 的偏移量为0处(即从abc.txt 的开头位置)读131072个字节”
客户端:“从0x531352e1 的偏移量为131072处(即接着上一个请求读完的位置)再读131072个字节”
服务器:“给你131072个字节”
服务器:“再给你131072个字节”
(继续读,知道读完整个文件)
就这样NFS完成了文件的读取过程,从最后几个包可见,linux客户端读NFS共享文件时是多个READ Call 连续发出去的(本例中是连续两个),这个方式跟windows xp 读CIFS 共享文件有所不同,windows xp不会连续发READ Call ,而是先发一个REAF Call,等收到Reply后再发下一个。相比之下,linux这种读方式比windows xp更高效,尤其是再高带宽、高延迟的环境下。这就像叫外卖一样,如果你今晚想吃鸡翅、汉堡和可乐三样食物,那合理的方式应该是打一通电话把三洋都叫齐了,而不是先叫鸡翅、等鸡翅送到了再叫汉堡、等汉堡送到后再叫可乐。
除了读文件的方式,每个READ Call 请求多少数据也会影响性能,在高性能环境中,要手动指定一个比较大的值,这个值可以在mount时通过rsize参数来定义,比如mount -o rsize=524288 10.32.106.62:/code /tmp/code
写过程
分析完读操作,接下来再看看写文件的过程,把一个名为abc.txt的文件写道NFS共享的过程如下

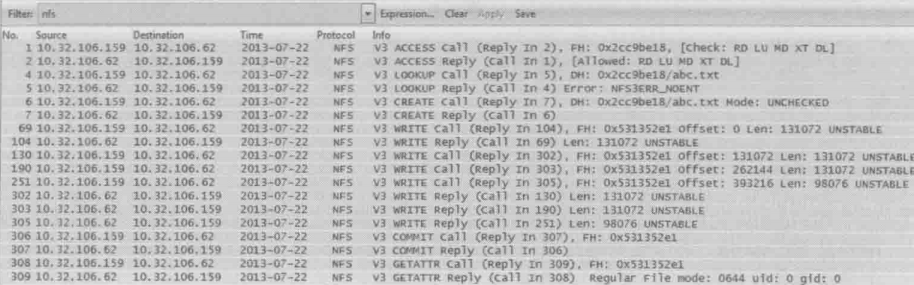
1和2号包

客户端:“我可以进入0x2cc9be18(即/code 目录)吗?”
服务器:”你的请求被接受了,进来吧“
4和5号包

客户端:“请问这里有叫abc.txt的文件吗?”
服务器:“没有”
注:
在创建一个文件之前,要先检查一下是否有同名文件存在,吐过没有才能继续写,如果有,要询问用户是否覆盖原文件
6和7号包

客户端:“那我想创建一个叫abc.txt的文件”
服务器:“没问题,这个文件的file handle时0x531352e1”
64、104、130和190号包

客户端:“从0x531352e1 的偏移量为0处(即abc.txt的文件开头)写131072个字节”
服务器:“第一个131072字节写好了”
客户端:“从0x531352e1 的偏移量为131072处(即接着上一个写完的位置)再写131072个字节”
客户端:“从0x531352e1 的偏移量为262144处(即接着上一个写完的位置)再写131072个字节”
(继续写,直到写完整个文件)
306和307号包

客户端:“我刚才往0x531352e1(也就是abc.txt)写的数据都存盘了吗?”
服务器:“都存好了”
注:
这是COMMIT操作,对于async方式的WRITE Call,服务器收到Call之后会在真正存盘前就回复WIRTE Reply,这样做是为了提高写性能,那么,客户端怎么知道哪些WIRTE Call已经真正存盘了呢?COMMIT 操作就是为此而设计的,只有COMMIT过的数据才算真正写好
308和309号包

客户端:“那我看看0x531352e1(也就是abc.txt)的文件属性”
服务器:“文件的权限、uid、gid、文件大小等信息都给你”
这个例子的写操作也是多个WIRTE Call连续发出去的(那为什么上面104号包是WRITE Reply?),这是因为我们在挂载时没有指定任何参数,所以使用了默认的async写方式
和async相对应的时sync方式
假如mount时使用了sync参数,客户端会先发送一个WRITE Call,等收到Reply后再发下一个Call,也就是说WRITE Call和WRITE Reply是交替出现的,除此以外,还有什么办法再包里看出一个写操作是async还是sync呢?每个WRITE Call上的“UNSTABLE”和“FILE_SYNC”标志,前者表示async,后者表示sync
下图显示了用sync参数后的网络包

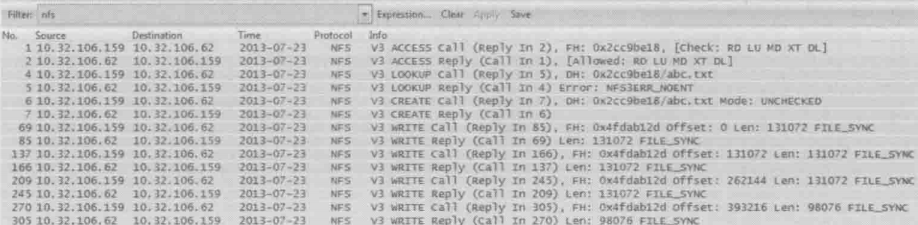
从上图中不仅可以看到FILE_SYNC标志,还可以看到WRITE Call和WRITE Reply是交替出现的(也就是说没有连续的CALL),不难想象,每个WRITE Call写多少数据也是影响写性能的重要因素,我们可以在mount时用 wsize参数来指定每次应该写多少,不过在有些客户端上启用sync参数之后,无论wsize定义成多少都会被强制为4KB,从而导致写性能非常差
那为什么还有人用sync方式呢?答案是有些特殊的应用要求服务器收到sync的写请求之后一定要等到存盘才能恢复WRITE Reply,sync操作正符合了这个需求,由此我们也可以推出COMMIT对于sync写操作师没有必要的
非常值得一提的是,经常有人在mount时使用noac参数,然后发现读写性能都有问题,而根据RFC的说明,noac只是让客户端不缓存文件属性而已,为什么会影响性能呢?
先看写文件的情况

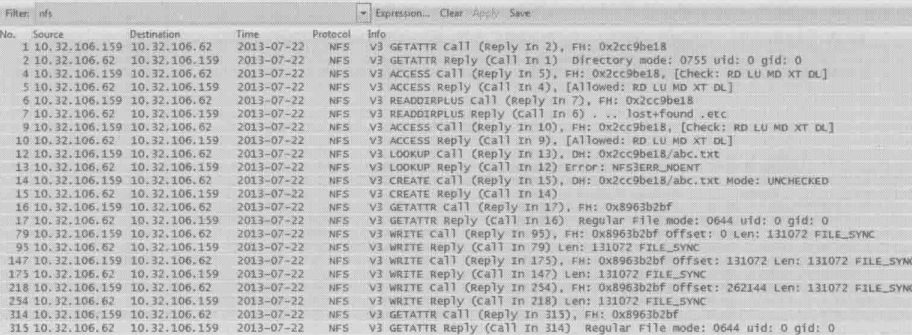
在上图中,从WRITE Call里的FILE_SYNC可以知道,虽然在mount时并没有指定sync参数,但是noac把写操作强制变成sync方式了,性能自然也会下降
再看读文件时的情况

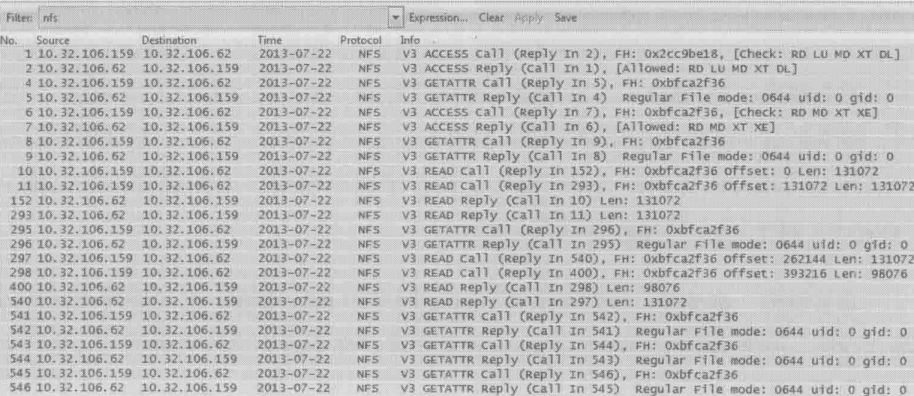
从上图可以看到,在读文件过程中,客户端频繁地通过GETATTR查询文件属性,所以读性能也受到了影响,在高延迟地网络中影响尤为明显
从wireshark看网络分层
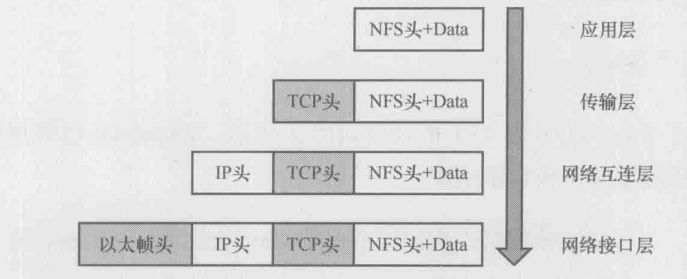
TCP/IP模型
前文已经介绍过NFS协议,我们便以它为例来学习网络分层
下图是客户端10.32.106.159往服务器10.32.106.62上写文件时抓的网络包
这5个包大概做了下面这些事
客户端:“我想创建test.txt”
服务器:“创建成功了(该文件的file handle 时0xf87a7de0,点开包才能看到)”
客户端:”我想写28个字节到该文件里(这些字节显示在上图的右下角)“
服务器:”收到了“
服务器:”写好了“
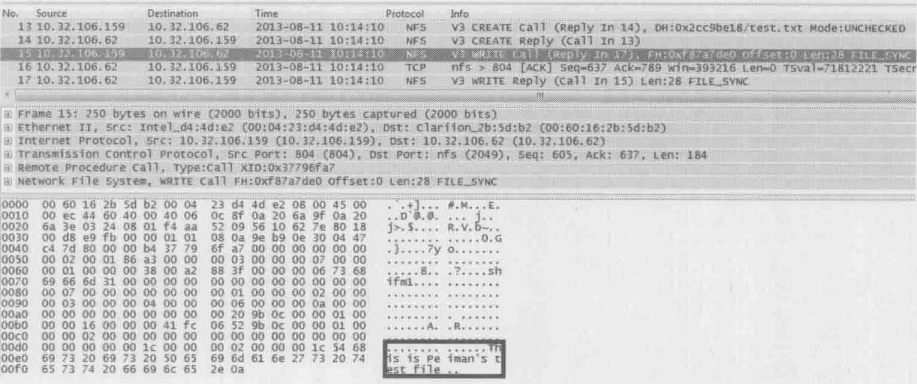
其中第三个包(编号为15)的详情如下图所示,wireshark已经形象地把这个包地内容用分层地结构显示出来
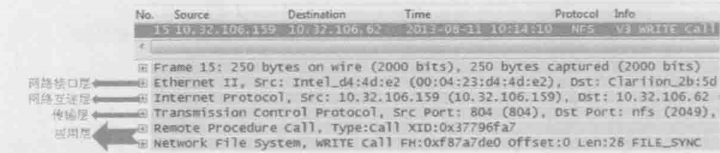
应用层:由于NFS是基于RPC(remote procedure call 远程过程调用)的协议,所以wireshark把它分成NFS和RPC两行来显示。仔细检查这一层的详细信息,会发现它只专注于文件操作,比如读或写,而对于数据传输一无所知。点开加号便能看到这个写操作的详情,比如用户的UID、文件的file handle和要写的字节数等
传输层:这一层用到了TCP协议。应用层所产生的数据就是由TCP来控制传输的,点开TCP层前的加号,我们可以看到Seq号和Ack号等一系列信息,它们用于网络包的排序、重传、流量控制等。虽然名曰”传输层“,但它并不把网络包从一个设备传到另一个,而只是对传输行为进行控制。真正负责设备间传输的是下面两层
网络互联层(网络层):在这个包中,本层的主要任务是把TCP层传下来的数据加上目标地址和源地址。有了目标地址,数据才可能送达接收方;而有了源地址,接收方才知道发送方是谁
网络接口层:从中可以看到相邻两个设备的MAC地址,因此该网络包才能以接力的方式送达目标地址
在这个例子中,我们可以看到网络分层就像是有序的分工,每一层都有自己的责任范围,上层协议完成工作后就交给下一层,最终形成一个完整的网络包
可以借下面这个例子便于理解
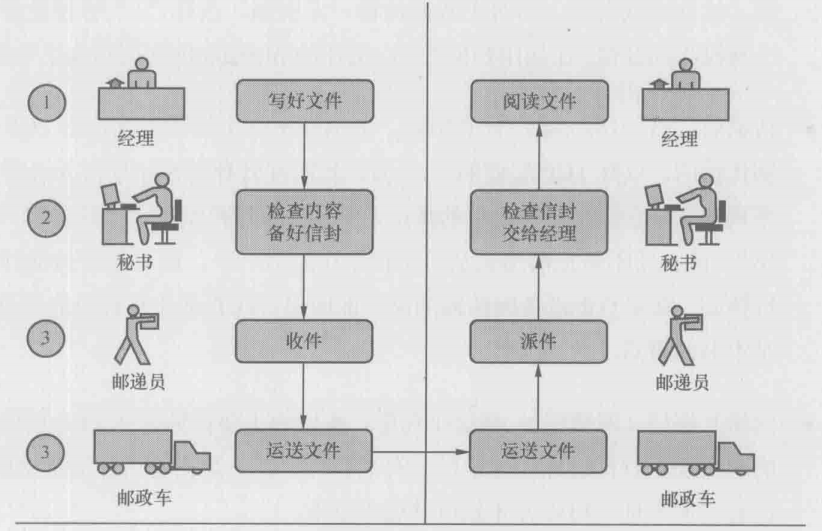
这个场景中的4个角色可以对应网络的4个层次,每个角色都有自己的分工,最终完成文件的送达
TCP和IP刚发明的时候就是和在一层的,后来才拆成两层。如果在经历和秘书之间加个助理,专门负责检查错别字,会有问题吗?与很多官僚作风严重的机构一样,多盖一个章就要多花一些时间。20世纪那场OSI七层模型与TCP/IP模型的竞争最终胜出的就是分层更简单的TCP/IP模型。要知道网络分层的目的并不仅仅是完成任务,而是要用最好的方式来完成
最大传输单元
理解了分层的基本概念,我们再来看看复杂一点的情况,如果这个写操作比较大,变成8192字节,TCP层又该如何处理?是否也是简单的加上TCP头就交给网络互连层(网络层)?
答案是否定的,因为网络对包的大小是有限制的,其最大值称为MTU(max transmission unit,最大传输单元),大多数网络的MTU是1500字节,但也有些网络启用了巨帧(jumbo frame),能达到9000字节
一个8192字节的包进入巨帧网络不会有问题,但到了1500字节的网络中就会被丢弃或者切分。被丢弃意味着传输彻底失败,因为重传的包还会再一次被丢弃,而被切分则意味这传输效率较低
由于这个原因,TCP不像简单地把8192字节地数据一口气传给网络互连层,而是根据双方的MTU决定每次传多少。知道自己的MTU容易,但对方的MTU如何获得呢?
如下图所示,在TCP连接建立(三次握手)时,双方都会把自己的MSS(maximum segment size,最大片段大小)告诉对方。MSS加上TCP头和IP头的长度就得到MTU了

在第一个包里,客户端声明自己的MSS是8960,意味着它的MTU就是8960+20(TCP头)+20(IP头)=9000;在第二个包里,服务器声明自己的MSS是1460,意味着它的MTU就是1460+20(TCP头)+20(IP头)=1500
下图是TCP连接建立之后的写操作,我们来看看究竟是哪个MTU起了作用
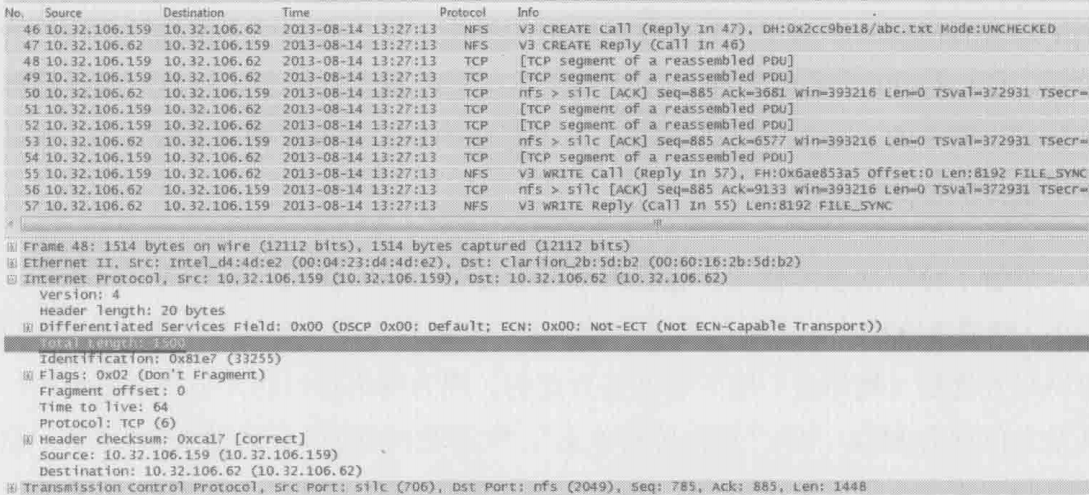
客户端在46号包创建了abc.txt,然后通过48、49、51、52、54和55号共6个包完成了这个8192字节的写操作。这些包的大小符合接收方的MTU1500字节(见上图中划线的Total Length:1500),而不是发送方本身支持的9000字节,也就是说,接收方的MTU起了决定作用
假如把客户端和服务器的MTU互换一下,这是客户端最大能发出多少字节的包呢?答案还是1500,因为无论接收方的MTU有多大,发送方都不能发出超过自己MTU的包。我们可以得到这样的结论:发包的大小是由MTU较小的一方决定的
TCP头部结构详解
TCP头部的标准长度为20字节,但最大可以达60字节,具体长度取决于是否包含可选字段(options)
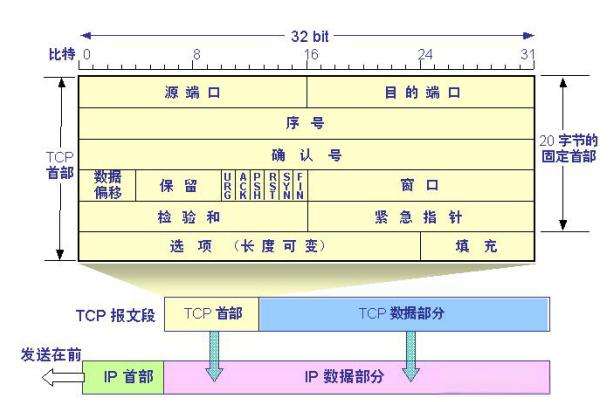
| 字段 | 长度(字节) | 说明 |
|---|---|---|
| 源端口(Source Port) | 2 | 发送方端口号 |
| 目的端口(Destination Port) | 2 | 接收方端口号 |
| 序列号(Sequence Number) | 4 | 用于可靠传输 |
| 确认号(Acknowledgment Number) | 4 | 期望收到的下一个字节序号 |
| 数据偏移(Data Offset) | 1(4 bits) | 定位数据开始的位置 |
| 保留+标志位(Reserved+Flags) | 1(含6个标志位:URG/ACK/PSH/RST/SYN/FIN) | 控制连接状态 |
| 窗口大小(Window Size) | 2 | 流量控制 |
| 校验和(Checksum) | 2 | 错误检测 |
| 紧急指针(Urgent Pointer) | 2 | 仅当 URG=1 时有效 |
| 选项(Options) | 0~40(可变) | MSS、时间戳等 |
| 填充(Padding) | 补齐到4字节对齐 | 保证头部是32位(4字节)的整数倍 |
IP头部结构详解
IP头部的标准长度和TCP头部的标准长度一样为20字节,同样最大可以达60字节,具体长度取决于是否包含可选字段(options)
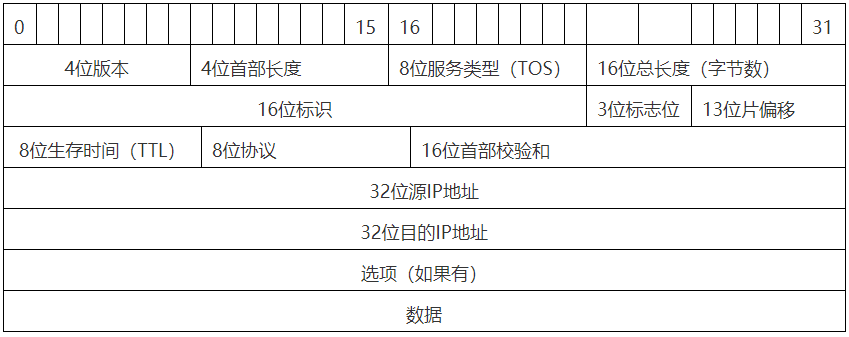
| 字段 | 长度 | 说明 |
|---|---|---|
| 版本(Version) | 4 bits | 表名IP地址为IPv4还是IPv6 |
| 首部长度(IHL,internet header length) | 4 bits | 表示IP头长度 |
| 服务类型(ToS/DSCP) | 1 byte | Qos优先级 |
| 总长度(Total Length) | 2 bytes | 整个IP包长度(头+数据) |
| 标识、标志、片偏移 | 4 bytes | 用于分片 |
| 生存时间(TTL) | 1 byte | 防止无限转发 |
| 协议(Protocol) | 1 byte | 上层协议(如TCP=6,UDP=17) |
| 头部校验和 | 2 bytes | 仅校验头部 |
| 源IP地址 | 4 bytes | 发送方地址 |
| 目的IP地址 | 4 bytes | 接收方地址 |
| 选项(Options) | 0~40 bytes(可变) | 可选选项 |
| 填充(Padding) | 补齐到4字节对齐 | 保证头部是4字节的整数倍 |
常见的协议和相应的协议字段如下表

TCP的连接启蒙
网络的传输层用于传递信息,它有两种方式——TCP和UDP,其中TCP是基于连接的(三次握手),而UDP不需要连接。它们各自支持一些应用层协议,但也有协议是两者都支持的,比如DNS。我们正好可以用DNS来比较TCP和UDP的差别
客户端10.32.106.159向DNS服务器10.32.106.103发起一个DNS查询,以获得paddy_cifs.nas.com所对应的IP地址
1.DNS默认使用UDP的情况下

这个过程所有的网络包如下图所示

2.用set vc 强制DNS使用TCP的情况下

这个过程所有的网络包如下图所示

从这两种情况的截图可以看到,真正起查询作用的只有两个DNS包
客户端:”paddy_cifs.nas.com 的IP是多少啊“
服务器:”是 10.32.106.77“
在使用UDP的情况下,的确只用了这两个包就完成了DNS查询,但在使用TCP时,要先用3个包(1、2和3号包)来建立连接。查询接收后,又用了4个包(7、8、9和10号包)来断开连接。wireshark把这两种情况的差别完全显示出来了,我们可以从中看到连接的成本远远超过DNS查询本身,这对繁忙的DNS服务器来说无疑时巨大的压力
nslookup命令
nslookup(name server lookup)是一个用于查询DNS(domain name system,域名系统)记录的命令行工具,广泛用于诊断DNS问题、查看域名解析结果或检查DNS服务器配置
TCP的工作原理
TCP参数
wireshark上能看到很多TCP参数,理解了它们就是学习TCP最好的开始
下图是10.32.106.159往10.32.106.62传数据的过程,我已经把一些参数用黑框标志出来,以便阅读时参照

Seq:表示该数据段的序号
TCP提供有序的传输,所以每个数据段都要表上一个序号,当接收方收到乱序的包,有了这个序号就可以重新排序了。我们不一定要知道Seq号的起始值是怎么算出来的,但必须理解它的增长方式。
如下图所示,数据段1的起始Seq号为1,长度为1448(意味这它包含了1448个字符),那么数据段2的Seq号就是1+1448=1449,数据段2的长度也是1448,所以数据段3的Seq号为1449+1448=2897。也就是说,一个Seq号的大小是根据上一个数据段的Seq号和长度相加而来的

上面的wireshark截屏也显示了相同的情况,51号包的Seq=3681,Len=1448,所以52号包的Seq=3681+1448=5129。这个Seq号是由这两个包的发送方,也就是10.32.106.159维护的
由于TCP是双向的,在一个连接中双方都可以是发送方,所以各自维护了一个Seq号。53号包和56号包的Seq号是10.32.106.62维护的,由于53号包的Seq=885,Len=0,所以56号包的Seq=885+0=885
Len:表示该数据段的长度
如上上张图中的Len=1448,注意这个长度不包括TCP头,虽然10.32.106.62发出的两个包Len=0,但其实是有TCP头的,头部本身携带的信息很多,所以不要意味Len=0就没意义
Ack:确认号
如上上张图中的Ack=6577,接收方向发送方确认已经收到了哪些字节
比如甲发送了”Seq:x Len:y“的数据段给乙,那乙回复的确认号就是x+y,这意味着它收到了x+y之前的所有字节。理论上,接收方回复的Ack号恰好就等于发送方的下一个Seq号,所以我们可以看到54号包的Seq也等于5129+1448=6577
你也许想问51号包为什么没有对应的确认包呢?其实53号包确认6577的时候,表示序号小于6577的所有字节都收到了,相当于把51号发送的字节也一并确认了,也就说TCP的确认是可以累计的
在一个TCP连接中,因为双方都可以是接收方,所以它们各自维护自己的Ack号。本例中10.32.106.32没有发送任何字节,所以10.32.106.158发出的Ack号一直不变
标志位
SYN
携带这个标志的包表示正在发起连接请求。因为连接是双向的,所以建立连接时,双方都要发一个SYN
FIN
携带这个标志的包表示正在请求终止连接。因为连接是双向的,所以彻底关闭一个连接时,双方都要发一个FIN
RST
用于重置一个混乱的连接,或者拒绝一个无效的请求
如下图所示,作者故意尝试连接一台linux服务器的445端口(一般只有windows上才开启这个端口,wireshark上把该端口显示位microsoft-ds),结果就被RST了,实际环境中的RST往往意味着大问题,如果你在wireshark中看到一个RST包,务必睁大眼睛好好检查

三次握手
了解了这些参数和标志位我们就可以学习TCP是如何管理连接的了,下图是一个标准的连接建立过程

这三个包就是传说中的”三次握手“,事实上,握手时Seq号并不是从0开始的,我们之所以在wiresahrk上看到Seq=0,是因为wireshark启用了 relative sequence number。如果你想关闭这个功能,可以在edit–>preference–>protocols–>TCP里设置
握手过程可以用下图来表示
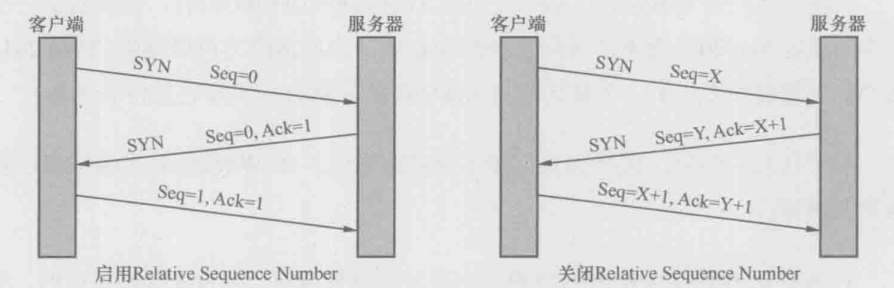
客户端:”我能跟你建立连接吗?我的初始发送序号时X,如果你答应就Ack=X+1“
服务器:”收到啦,Ack=X+1,我也想跟你建立连接,我的初始发送序号时Y,如果你答应连接就Ack=Y+1“
客户端:”收到啦,Ack=Y+1“
为什么要用三个包来建立连接呢,用两个不可以吗?其实也是可以的,但两个不够可靠。我们可以设想一个情况来说明这个问题:某个网络有多条路径,客户端请求建立连接的第一个包跑到一条延迟严重的路径上了,所以迟迟没有到达服务器,因此客户端只能当作这个请求丢失了,不得不再请求一次。由于第二个请求走了正确的路径,所以很快完成工作并关闭了连接。对于客户端来说,事情似乎已经结束了,没想到它的第一个请求经过跋山涉水,还是到达了服务器,如下图所示,服务器并不知道这是一个旧的无效请求,所以按照惯例回复了。假如TCP只要求两次握手,服务器上就这样建立了一个无效的连接,而在三次握手的机制下,客户端收到服务器的回复时,知道这个连接不是它想要的,所以就发一个拒绝包,服务器收到这个包后也放弃这个连接
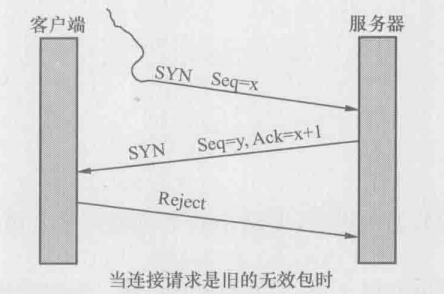
四次挥手
经过三次握手之后,连接就建立了,双方可以利用Seq、Ack和Len等参数互传数据,传完之后如何断开连接呢?下图就是TCP断开连接的”四次挥手“过程

客户端:”我希望断开连接(请注意FIN标志)“
服务器:”知道了,断开吧“
服务器:”我这边的连接也想断开(请注意FIN标志)“
客户端:”知道了,断开吧“
工作中如果碰到断开连接的问题,可以使用netstat命令来排查,无论在windows还是linux上,这个命令都能把当前的连接状态显示出来,不过老话常说,最推荐的工具还是wireshark
快递员的工作策略——TCP窗口
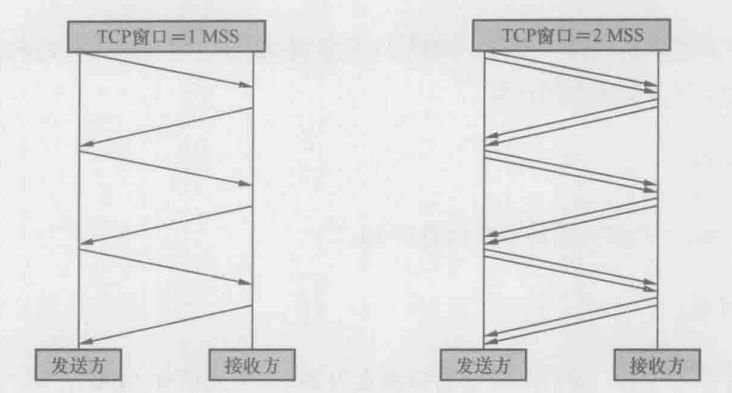
TCP有往返的需要,因为发包之后并不知道对法昂能否收到,要一直等到确认包到达,这样就花费了一个往返时间。假如每发一个包就停下来等确认,一个往返时间里就只能传一个包,这样的传输效率太低了,最快的方式应该是一口气把所有包发出去,然后一起确认,但显示中也存在一些限制:接收方的缓存(接收窗口)可能一下子接收不了这么多数据;网络的带宽也不一定足够大,一口气发太多会导致丢包事故。所以,发送方要知道接收方的接收窗口和网络这两个限制因素中哪一个更严格,然后在其限制范围内尽可能发多包,这个一口气能发送的数据量就是传说中的TCP发送窗口
发送窗口对性能的影响有多大?一图胜千言,下图显示了发送窗口为1个**MSS(maximum segment size,最大片段大小,即每个TCP包所能携带的最大数据量)**和2个MSS时的差别。在相同的往返时间里,右边比左边多发了一倍的数据量,而在真实环境中,发送窗口常常可以达到数十个MSS
下图就是在真是环境中抓的包,抓包时服务器10.32.106.73 正往客户端10.32.106.103 发数据,由于服务器的发送窗口很大,所以收到读请求之后,它在没有客户端确认的情况下连续发了10个包
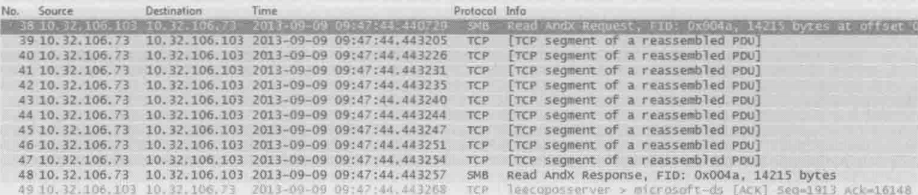
图1
接着作者把客户端的接收窗口强制修改成2920,相当于两个TCP包能携带的数据量。从下图中可以看到客户端通过”win=2920“把自己的接收窗口靠苏服务器,因此服务器把发送窗口限制为2920,每发两个包就停下来等待客户端的确认。同样一个14215字节的读操作,图1只用一个往返时间就完成了,而图2则用了6个
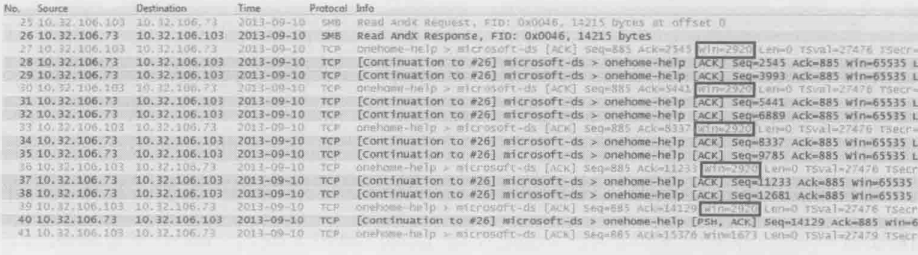
图2
为了更好地说明这个过程,作者把27号包到32号包用对话地形式表示出来,括号内的文字为作者添加的注释
客户端:“当前我的接收窗口是2920”
服务器:“(好,那我的发送窗口就定为2920)先给你1460字节”
服务器:“再给你1460字节,(哎呀!我的发送窗口2920用完了,不能再发了)”
客户端:“你发过来的2920字节已经处理完毕,所以现在我的接收窗口又恢复到2920”
服务器:“(好,那我再把发送窗口定位2920)给你1460字节”
服务器:“再给你1460字节(哎呀!我的发送窗口2920又用完了,不能再发了)”
这个例子只提到了接收窗口对发送窗口的限制,由于网络的影响方式非常复杂,所以本文暂时跳过
常见的问题
1.如下图所示,每个包的TCP层都含有“window size”(也就是win= )的信息,这个值表示发送窗口的大小吗?
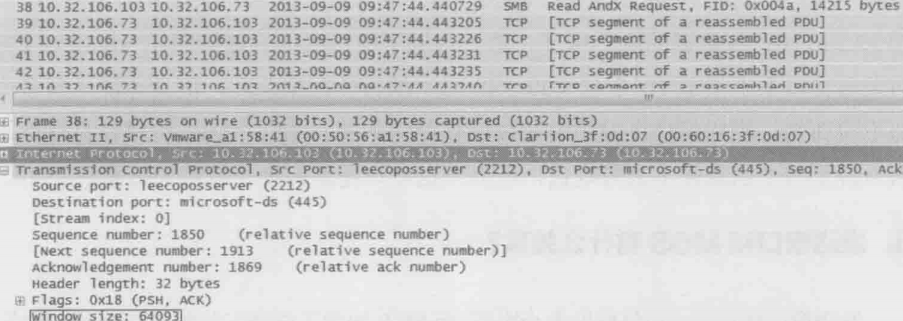
这不是发送窗口,而是在向对方声明自己的接收窗口。在此例子中,10.32.106.103向10.32.106.73声明自己的接收窗口时64093字节,10.32.106.73收到之后,就会把自己的发送窗口限制在64093字节之内
假如接收方处理数据的速度跟不上接收数据的速度,缓存就会被占满,从而导致接收窗口为0。如下图所示,80.0.0.85持续向89.0.0.210声明自己的接收窗口是win=0,所以89.0.0.210的发送窗口就被限制为0,意味着那段时间发不出数据

2.我如何在包里看出发送窗口的大小呢?
很遗憾,没有简单方法,有时候甚至完全没有办法。因为当发送窗口时由接收窗口决定的时候,我们还可以通过“window size”的值来判断,而当它由网络因素决定的时候,事情就会变得非常复杂,大多数时候,我们甚至不确定哪个因素在起作用,只能大概推理,以上图为例,接收方声明它的接收窗口等于0,那接收窗口肯定起了限制作用(因为不可能再小了),因此可以大胆地判断发送窗口就是0。再回顾本文开头10.32.106.73向10.32.106.103传数据地两个例子,第一个例子中,我们只能推理出10.32.106.73的发送窗口不小于那10个包(39~48号包)携带的数据总和,但具体能达到多少却不得而知,因为窗口还没用完时读操作就完成了,第二个例子比较容易分析,因为传了两个包就停下来等确认,所以发送窗口是那两个包携带的数据量2920
3.发送窗口和MSS有什么关系?
发送窗口决定了一口气能发多少字节,而MSS决定了这些字节要分多少个包发完。举个例子,再发送窗口为16000字节的情况下,如果MSS是1000字节,那就需要发送16000/1000=16个包;而如果MSS等于8000,那要发送的包数就是16000/8000=2了
4.发送方在一个窗口里发出n个包,是不是就能收到n个确认包?
不一定,确认包一般会少一些。由于TCP可以累计起来确认,所以当收到多个包的时候,只需要确认最后一个就可以了。比如本文中10.32.106.73向10.32.106.103传数据的第一个例子中,客户端用一个包(49号包)确认了它收到的10个包(39~48号包)
5.经常听说“TCP Window Scale”这个概念,它究竟和接收窗口有何关系?
在TCP刚被发明的时候,全世界的网络带宽都很小,所以最大接收窗口被定义成65535字节,随着硬件的革命性进步,65535字节已经称为性能瓶颈了,怎么才能扩展呢?TCP头中只给接收窗口留了16 bit,肯定是无法突破65535(2^16-1)的
1992年的RFC 1323 中提出了一个解决方案,就是在三次握手时,把自己的window scale信息告知对方,由于window scale放在TCP头之外的options中,所以不需要修改TCP头的设计。window scale的作用是向对方声明一个shift count,我们把它作为2的指数,再乘以TCP头中定义的接收窗口,就得到真正的TCP接收窗口了
以下图为例,从底部可以看到10.32.106.159告诉10.32.106.103说它的shift count是5,2^5=32,这就意味着以后10.32.106.159声明的接收窗口要乘以32才是真正的接收窗口值
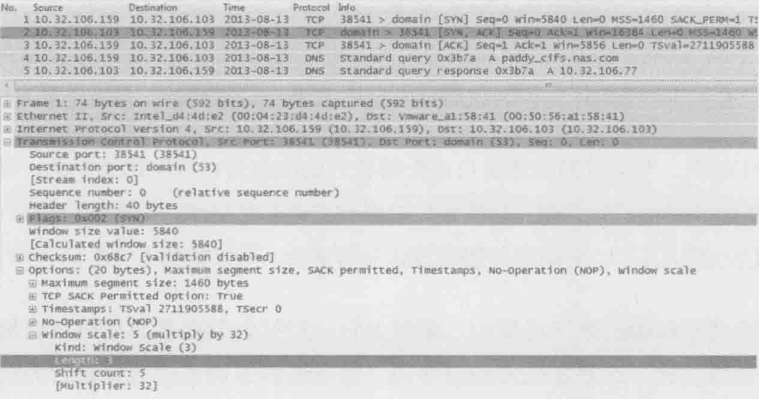
接下来我们再看下图中的3号包,10.32.106.159声明·它的接收窗口为”Window size value:183“,183乘以32得到5826,所以wireshark就显示出”Win=5826“了。要注意wireshark是根据shift count计算出这个结果的,如果抓包时没有抓到三次握手,wireshark就不知道该如何计算,所以我们有时候会莫名地看到一些极小地接收窗口值,还有些时候时防火墙识别不了window scale,因此对方无法获得shift count,最终导致严重地性能问题
重传的讲究
如何维护拥塞窗口
网络之所以能限制发送窗口,是因为它一口气收到太多数据时就会拥塞。拥塞的结果是丢包,这是发送方最忌惮的。能导致网络拥塞的数据量称为拥塞点。发送方当然希望把发送窗口控制再拥塞点以下,这样就能避免拥塞了,但问题是连网络设备都不知道自己的拥塞点,即便知道了也无法通知发送方,这种情况下发送方如何避免触碰拥塞点呢?
方案1:发送方知道自己的网卡带宽,能否以此推测该连接的拥塞点?
不能,因为发送方和接收方之间还有路由器和交换机,其中任何一个设备都可能是瓶颈。比如发送方的网卡是10Gbit/s,而接收方只有1Gbit/s,如果按照10Gbit/s计算肯定会出问题。就算用1Gbit/s来计算也没有意思,因为网络带宽是多个连接共享的,其他连接也会占用一定带宽
方案2:主机增加发送量,直到网络发生拥塞,这样得到的最大放松两能定为该连接的拥塞点吗?
这是一个好办法,但没这么简单,网络就像马路一样,有的时候很堵,其他时候却很空,所以拥塞点是一个随时改变的动态值,当前试探出的拥塞点不能代表未来
难道就没有一个完美的方案吗?很遗憾,还真的没有,幸好经过几代人的努力,总算有了一个最靠谱的策略,这个策略就是在发送方维护一个虚拟的拥塞窗口,并利用各种算法使它尽可能接近真实的拥塞点。网络对发送窗口的限制就是通过拥塞窗口实现的,下面我们就来看看拥塞窗口如何维护
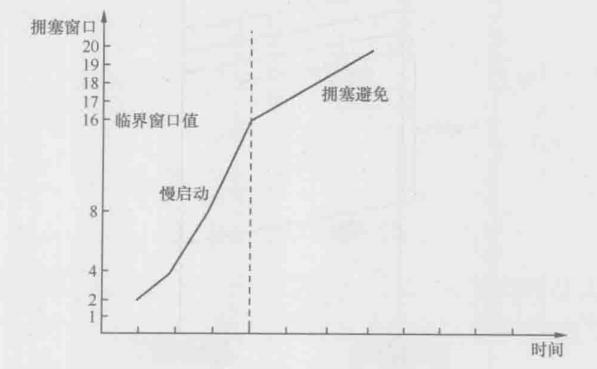
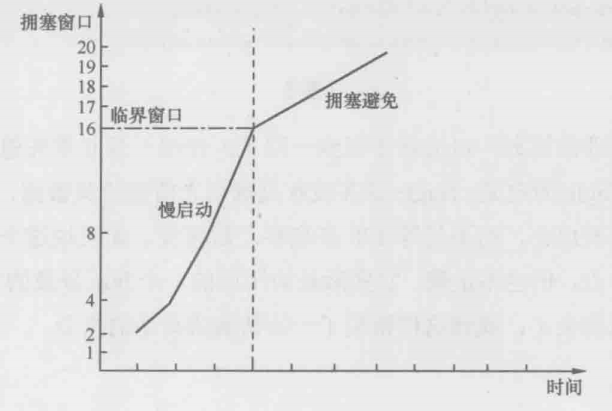
1.连接刚刚建立的时候,发送方对网络状况一无所知,如果一口气发太多数据就可能遭遇拥塞,所以发送方把拥塞窗口的初始值定的很小。RFC的建议是2个、3个或者4个MSS,具体视MSS的大小而定
2.如果发出去的包都得到确认,表明还没有达到拥塞点,可以增大拥塞窗口。由于这个阶段发生拥塞的概率很低,所以增速应该快一些。RFC建议的算法是每收到n个确认,可以把拥塞窗口增加n个MSS。比如发了2个包之后收到2个确认包,拥塞窗口就增大到2+2=4,接下来是4+4=8,8+8=16 ……这个过程的增速很快,但是由于基数低,传输速度还是比较慢的,所以被称为慢启动过程
3.慢启动过程持续一段时间后,拥塞窗口达到一个较大的值,这时候传输速度比较快,触碰拥塞点的概率也大了,所以不能继续采用翻倍的慢启动算法,而是要缓慢一点。RFC建议的算法是在每个往返时间增加1个MSS。比如发了16个MSS之后全部被确认了,拥塞窗口就增加到16+1=17个MSS,再接下去是17+1-18,18+1=19…...这个过程称为拥塞避免。从慢启动过渡到拥塞避免的临界窗口值很有讲究,如果之前发生过拥塞,就把该拥塞点作为参考依据;如果从来没有拥塞过就可以取相对较大的值,比如和最大接收窗口相等,全过程可以用下图表示
无论是慢启动还是拥塞避免阶段,拥塞窗口都在逐渐增大,理论上一定时间之后总会碰到拥塞点的,那为什么我们平时感觉不到拥塞呢?原因有很多,如下所示
1.操作系统中对接收窗口的最大设定多年没有改动,比如windows再不启用“TCP window scale option”的情况下,最大接收窗口只有64KB,而近年来网络有很长足进步,很多环境的拥塞点远在64KB以上,也就是说发送窗口已经被限制再64KB了,永远触碰不到拥塞点
2.很多应用场景是交互式的小数据,比如网络聊天,所以也不会有拥塞的可能
3.在传输数据的时候如果采用同步方式,可能需要的窗口非常小。比如采用了同方式的NFS写操作,每写一个写请求就停下来等回复,而一个写请求可能只有4KB
4.即便偶尔发生拥塞,持续时间也不足以长到感受出来,除非抓了网络包进行数据分析
超时重传
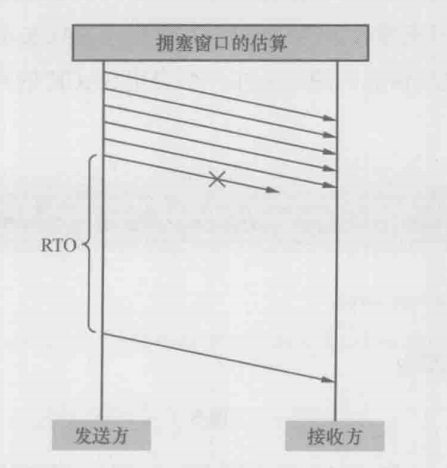
拥塞之后会发生什么情况呢?对发送方来说,就是发出去的包不像往常一样得到确认了,不过收不到确认也可能是网络延迟所致,所以发送方决定等待一小段时间后再判断,假如迟迟收不到,就认定包已经丢失,只能重传了。这个过程称为超时重传。如下图所示,从发出原始包到重传该包的这段时间称为RTO(timeout retransmission)。有些操作系统上提供了调节RTO大小的参数
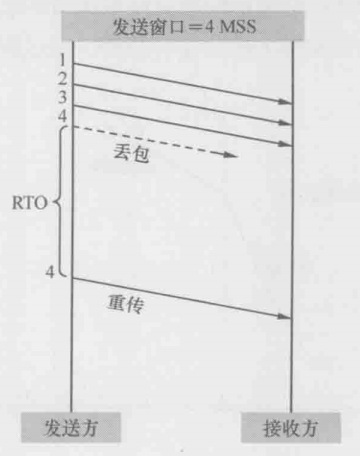
重传之后的拥塞窗口是否需要调整呢?非常有必要,为了不给刚发生拥塞的网络雪上加霜,RFC建议把拥塞窗口降到1个MSS,然后再次进入慢启动过程,这一次从慢启动过度到拥塞避免的临界窗口值就有参考依据了。(我第一次阅读的时候不理解为什么超时重传了要将拥塞窗口讲到1MSS,这样不会特别慢吗,经过搜索了解超时重传和快速重传的性质不一样,超时重传触发条件是长时间没有收到一个Ack,而快速重传往往只触发于局部丢包,超时重传意味着严重拥塞或网络中断,若此时仍然保持较大MSS,继续发送大量数据,会加剧拥塞,甚至导致拥塞崩溃。可以说讲拥塞窗口降为1MSS是一种极度保守的策略,确保只发一个报文探路,如果这个报文能成功Ack,说明网络开始恢复,再通过慢启动逐步探测可用带宽)
Richard Stevens在《TCP/IP Illustrated》中把临界窗口值定为上次发生拥塞时的发送窗口的一半。
而RFC 5681 则认为应该是发生拥塞时没被确认的数据量的1/2,但不能小于2个MSS。比如说发了19个包出去,但只有前3个包收到确认,那么临界窗口值就被定为后16个包携带的数据量的1/2
下图显示了发生超时重传时拥塞窗口的变化
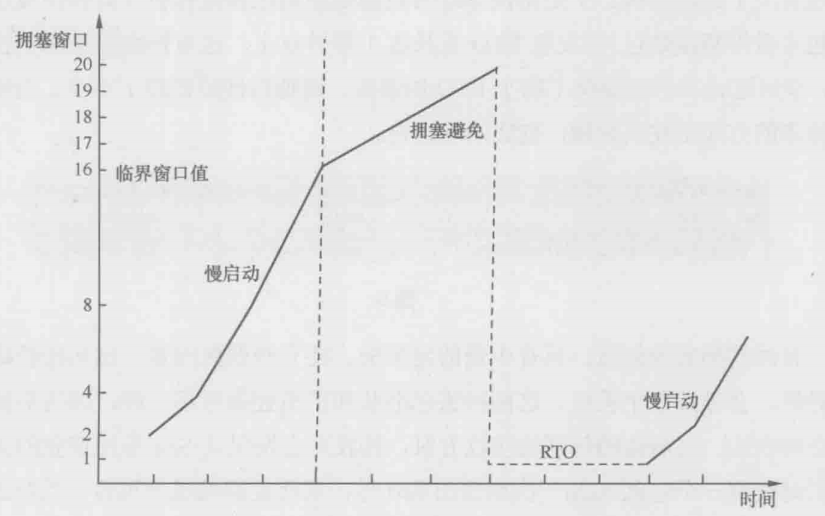
不难想象,超时重传对传输性能有严重影响。原因之一是在RTO阶段不能传数据,相当于浪费了一段时间;原因之二是拥塞窗口的急剧减小,相当于接下来传得慢多了。以作者的个人经验,即便是万分之一的超时重传对性能的影响也非同小可
我们在wireshark中如何查看重传情况呢?单击analyze–>expert infomation,就能在看到了,如下图所示,点开>号还能看到具体是哪些包发生了重传
下图是作者处理过的一个真实案例,从note标签中看到Seq号为1458613的包发生了超时重传,于是用该Seq号过滤出原始包和重传包(只有在发送方抓的包才看得到原始包),发现RTO竟长达1秒钟以上,这对性能的影响实在太大了,幸好这台发送方提供了缩小RTO的参数,调整后性能提高了不少,当然治标又治本的方式是找出瓶颈,彻底消除重传

快速重传
有时候拥塞很轻微,只有少量的包丢失。还有些偶然因素,比如校验码不对的时候,会导致单个丢包。这两种丢包症状和严重拥塞时不一样,因为后续有包能正常到达。当后续的包到达接收方时,接收方会发现其Seq号比期望的大,所以它每收到一个包就Ack一次期望的Seq号,一次提醒发送方重传。当发送方收到3个或以上重复确认(Dup Ack)时,就意识到相应的包已经丢了,从而立即重传它。这个过程称为快速重传。之所以称为快速,是因为它不像超时重传一样需要等待一段时间
下图是作者处理过的另一个真实案例。客户端发送了1182、1184、1185、1187、1188共5个包,其中1182在路上丢了。幸好到达服务器的4个包触发了4个Ack=991851,所以客户端意识到丢包了,于是在1337号包快速重传了Seq=991851

为什么要规定凑满3个呢?这是因为网络包有时会乱序,乱序的包一样会触发重复的Ack,但是为了乱序而重传没有必要。由于一般乱序的距离不会相差太大,比如2号包也许会跑到4号包后面,但不太可能跑到6号包后面,所以限定成3个或以上可以在很大程度上避免因乱序而触发快速重传。如下图中的左图所示,2号包的丢失凑满了3个Dup Ack,所以触发快速重传,而右图的2号包跑到4号包后面,却因为凑不满3个Ack而没有触发快速重传
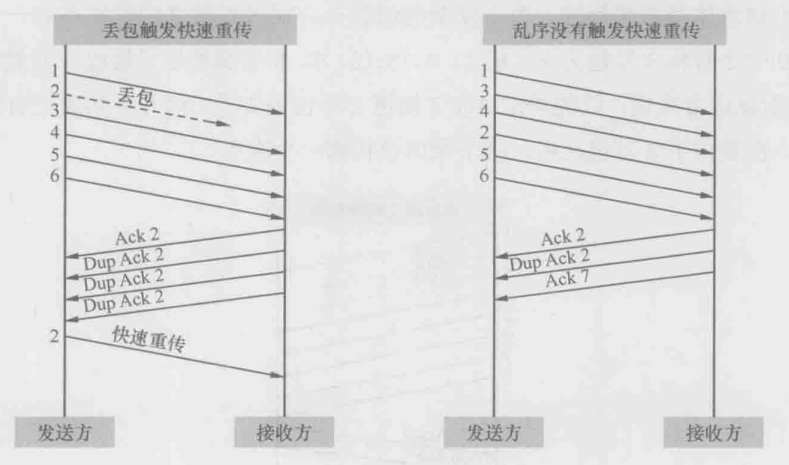
乱序
为什么网络包会乱序?
1.路由路径变化
现代互联网中,数据包可能通过不同的路径(如不同路由器、链路)传输。如果网络拓扑动态调整(如某条链路拥塞),后续数据包可能被转发到另一条延迟更短或更长的路径上,这样就可能导致后发的数据包先到,导致乱序
2.中间设备处理差异
路由器、交换机等网络设备对不同数据包的处理时间可能不同
3.并行发送或分片重组
在高速网络中,发送端可能使用多个队列或通道并行发送数据,IP分片后的包在接收端重组是也可能因为分片到达顺序不同而表现为乱序
4.无线网络干扰或重传机制
在Wi-Fi或移动网络中,某些包因信号差被重传,而其他包正常到达也会造成乱序
为什么乱序的包序号一般不会相差太大?
这个问题的核心在于网络传输的局部性和TCP的滑动窗口机制
1.TCP使用滑动窗口(sliding window)控制并发发送量
发送方一次只能发送发送窗口范围内的数据,因此,在任意时刻,网络中流通的数据包对应的序列号范围是有限的,即使发生乱序,也只是在这个窗口范围内打乱,不会出现序号跳跃极大的情况
2.网络路径延迟差异有限
虽然不同路径有不同延迟,但通常差异在几十毫秒到几百毫秒,在这个时间窗口内,发送方只发送有限数量的数据包,所以乱序通常表现为相邻几个包顺序颠倒,而不是远距离跳跃
3.接收方缓冲区容量限制
接收方只会缓存期望序号附近的乱序包,若序号差距过大(超出接收窗口),接收方可能直接丢弃或视为异常。因此,即使极端情况下有大跨度乱序,也往往不会被正常处理,从而观察不到
4.实际网络中突发性乱序通常是局部的
根据大量实测数据,绝大多数乱序时间涉及的序号偏移不超过几个MSS
快速恢复
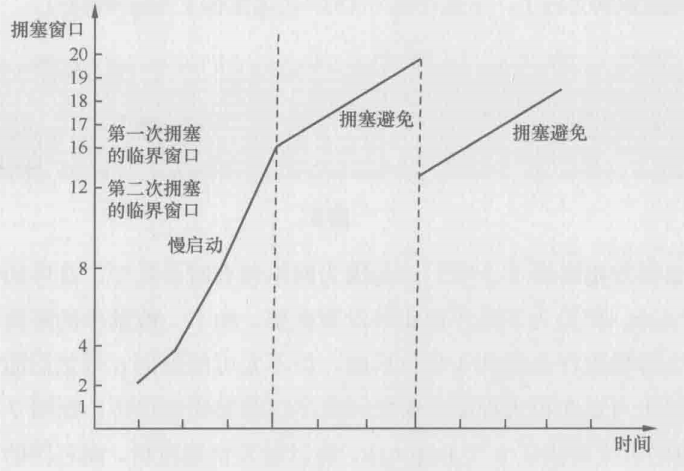
如果在拥塞避免阶段发生了快速重传,是否需要像发生超时重传一样处理拥塞窗口呢?完全没有必要——既然后续的包都到达了,说明网络并没有严重拥塞。接下来传慢点就可以了。RFC 5681认为临界窗口值应该设为发生拥塞时还没被确认的数据量的1/2(但不能小于2个MSS)。然后将拥塞窗口设置为临界窗口值加3个MSS,继续保留在拥塞避免阶段。这个过程称为快速恢复,其拥塞窗口的变化大概可以用下图表示
多个丢包时的重传方案(NewReno、SACK)
更复杂的情况是很多时候丢的包并不知一个。比如下图中2号包和3号包丢失,但1、4、5、6、7、8号都到达了接收方并触发Ack2。对于发送方来说,只能通过Ack 2 直到2号包丢失了,但并不知道还有哪些包丢失,所以在重传了2号包之后,接下来应该传哪一个呢?
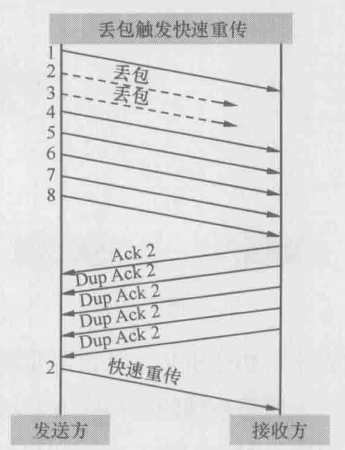
方案1:不管三七二十一,把3、4、5、6、7、8号6个包都重传一遍。这个方案简单直接,但是丢一个包的后果就是多个包被重传,效率很低。早期的TCP协议就是这样处理的
方案2:接收方收到重传过来的2号包之后,会回复一个Ack 3,因此发送方可以推理出3号包也丢了,把它也重传一遍。当接收方收到重传的3号包之后,因为丢包的窟窿都补满了,所以回复一个Ack 9,从此发送方就可以传新的包。这个方案称为NewReno,由RFC 2582 和RFC 3782定义。NewReno在本例中看上去很理想,但我们可以想象到当丢包量很大的时候,就需要花费多个RTT(round-trip time 往返时间)来重传所有丢失的包
方案3:接收方在Ack 2号包的时候,顺便把收到的包号告诉发送方,所以这些Ack包应该是这样的:
收到4号包时,告诉发送方:“我已经收到4号包,请给我2号包”
收到5号包时,告诉发送方:“我已经收到4、5号包,请给我2号包”
收到6号包时,告诉发送方:“我已经收到4、5、6号包,请给我2号包”
……
因此发送方对丢包细节了如指掌,在快速重传了2号包之后,它可以接着传3号包,然后再传9号包。这个非常直观的方案称为SACK,由RFC 2018定义
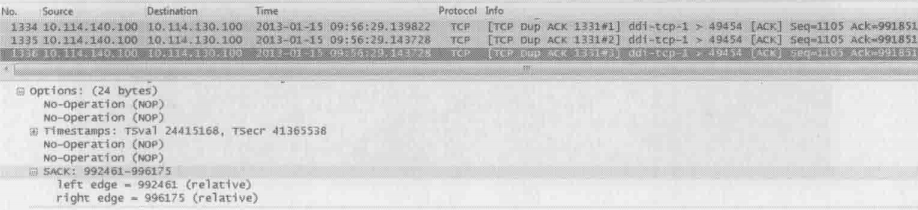
下图就是在真实环境中抓到的SACK实例。把“SACK=992461-996175”和“Ack=991851”两个条件综合起来,发送方就知道992461996175已经收到了,而前面的991851992460反而没收到
本文结论
没有拥塞时,发送窗口越大,性能越好。所以在带宽没有限制的条件下,应该尽可能增大接收窗口,比如启用Scale Option
如果经常发生拥塞,那限制发送窗口反而能提高性能,因为即便万分之一的重传对性能的影响都很大。在很多操作系统上可以通过限制接收窗口的方法来减小发送窗口
超时重传对性能影响最大,因为它有一段时间(RTO)没有传输任何数据,而且拥塞窗口会被设成1MSS,所以要尽量避免超时重传
快速重传对性能影响小一些,因为它没有等待时间,而且拥塞窗口减小的幅度没那么大
SACK和NewReno有利于提高重传效率,提高传输性能
丢包对极小文件的影响比大文件严重。因为读写一个小文件需要的包数很少,所以丢包时往往凑不满3个Dup Ack,只能等待超时重传了;而大文件有较大可能触发快速重传。下面的实验显示了同样的丢包率对大小文件的不同影响:
图一中的test时包含很多小文件的目录,而图2的hi时一个大文件。发生丢包时前者耗时增加了7倍多,而后者只增加了不到4倍
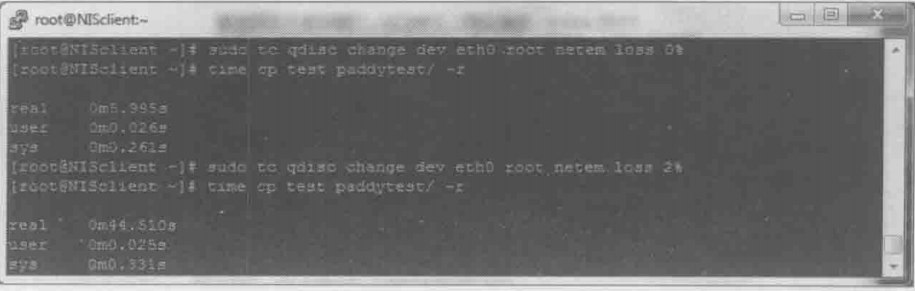
图1
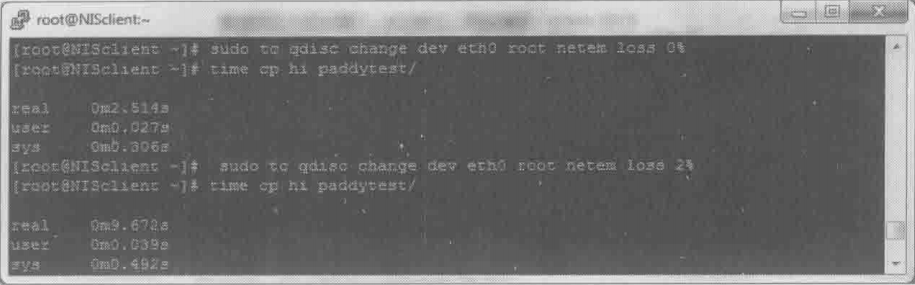
图2
延迟确认与Nagle算法
延迟确认
发送窗口一般只影响大块的数据传输,比如读写大文件。而频繁交互的小块数据不太在乎发送窗口的大小,因为发包量本来就少。日常生活中这样的场景很多,比如用SSH客户端连接一台linux服务器,然后随便输入一些字符,在网络上就交互了很多小块数据了。假如把这个过程的包抓下来,会看到很多小包频繁来往于客户端和服务器之间。这种方式其实是很低效的,因为一个包的TCP头和IP头至少就40字节,而携带的数据却只有一个字符
作者做了一个实验来研究这个现象。现在SSH客户端上缓慢的输入3个字符“j”,每次按键的间隔在300毫秒以上,这时候wireshark抓到了前9个包。接着快速敲击键盘,wireshark由抓了后面的包,wireshark截屏如下图所示
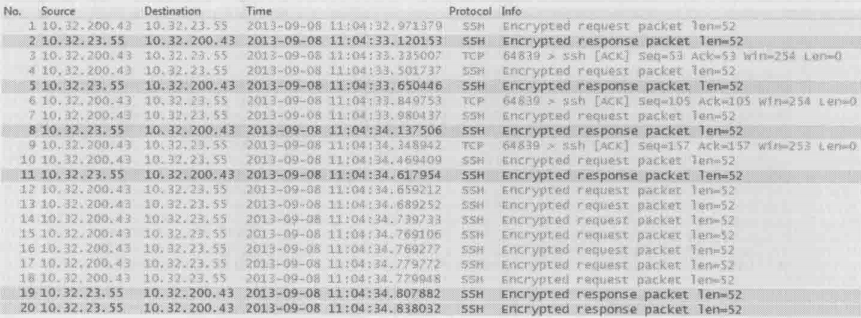
前三个包含义如下
客户端:“我想给你发个加密后的字符‘j’”
服务器:“我收到字符‘j’了,你可以把它显示出来”
客户端:“知道了”
接下来的4、5、6号包,以及7、8、9号包也是一样的情况
作者的客户端10.32.200.43放在上海,而服务器10.32.23.55位于悉尼,它们之间的往返时间大概是150毫秒。由于这些包是在客户端收集的,所以1号包和2号包相差150毫秒是正常现象。奇怪的是客户端收到2号包之后,竟然等了大约200毫秒才发出3号包。本来是1毫秒之内可以完成的事,为什么要等这么久呢?再看看5号和6号包之间,以及8号和9号包之间,也是大概相差200毫秒
这其实就是TCP处理交互式场景的策略之一,称为延迟确认。该策略的原理是:如果收到一个包之后暂时没什么数据要发给对方,那就延迟一段时间(在windows上默认为200毫秒)再确认。假如再这段时间里恰好有数据要发送,那确认信息和数据就可以再一个包里发出去了。第12个包就恰好符合这个策略,客户端收到11号包之后,等了41毫秒左右时我又输入一个字符,结果这个字符和对11号包的确认信息就一起装在12号包里了
延迟确认并没有直接提高性能,它只是减少了部分确认包,减轻了网路负担。有时候延迟确认反而会影响性能。微软的 KB328890 提供了关闭延迟确认的步骤。作者再另一台客户端10.32.200.131 上实施这些步骤后,结果如下图所示,国探不到1毫秒就发确认了(参见6号包和7号包的时间差)

Nagle算法
仔细看上面两张图,会发现每个SSH Request 都是52字节,这表明了它只包含了一个加密的字符。虽然在第一张图的12号到18号包之间的100毫秒里(还不到一个往返时间),一共输入了7个字符,但这些字符也被逐个打成小包了,能不能设计一个缓冲机制,把一个往返时间里生成的小数据收集起来,合并成一个大包呢?Nagle算法就实现了这个功能。这个算法的原理是:在发出去的数据还没有被确认之前,假如又有小数据生成,那就把小数据收集起来,凑满一个MSS或者等收到确认后再发送。下图是启用Nagle之后的新实验,第一包把输入的第一个字符发出去了。再收到确认包之前的150毫秒里,又输入了6个字符,这个6个字符并没有被逐个发送,而是被收集起来,等收到2号包之后,从3号包里一起发送,这就是为什么3号包携带的数据长度是312字节
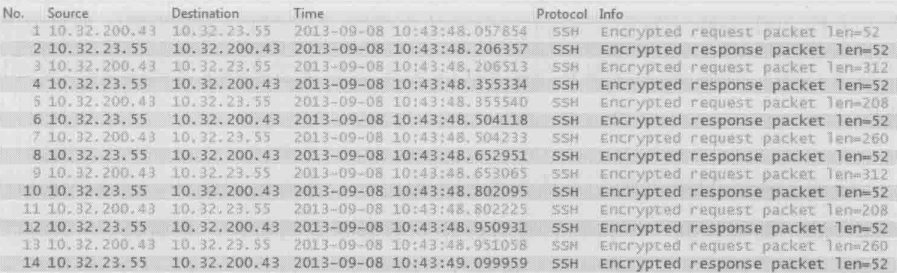
和延迟确认一样,Nagle也没有直接提高性能,启用它的作用只是提高传输效率,减轻网络负担。在某些场合,比如和延迟确认一起使用是甚至会降低性能。
百家争鸣
Westwood
《TCP/IP Illustrated,Volume 1:The Protocols》中介绍了一个叫“临界窗口值”的概念,当拥塞窗口处于临界窗口值以下时,就用增速较快的慢启动算法;当拥塞窗口升到临界窗口值以上时,则改用增速较慢的拥塞避免算法。从下图可见,临界窗口前后的斜率有明显的变化。这个机制有利于拥塞窗口在最短时间到达高位,然后保持尽可能长的时间才触碰拥塞点,思路还是很科学的
那临界窗口应该如何取值才合理呢?作者想到的是在带宽大的环境中取得大一些,在带宽小的环境中取得小一些。RFC 2001 也是这样建议的,它把临界窗口值定义为发生丢包是拥塞窗口的一半大小。我们可以想象在带宽大的环境中,发生丢包时的拥塞窗口往往也比较大,所以临界窗口值自然会随之加大。可以用下面的例子来加以说明
图1在拥塞窗口为16个MSS时发生了丢包,而图2在拥塞窗口为8个MSS时就丢包了,说明当时图1中的带宽很可能比图2中的大。根据RFC 2001,我们希望接下来图1的拥塞窗口能快速恢复到临界窗口值16/2=8个MSS,然后再缓慢增加;也希望图2中的拥塞窗口能快速恢复到临界窗口值8/2=4个MSS,然后再缓慢增加。这样做的结果就是图1的拥塞窗口比图2的增长得更快,更配的起它的带宽。以上这些分析,看上去很有道理吧?
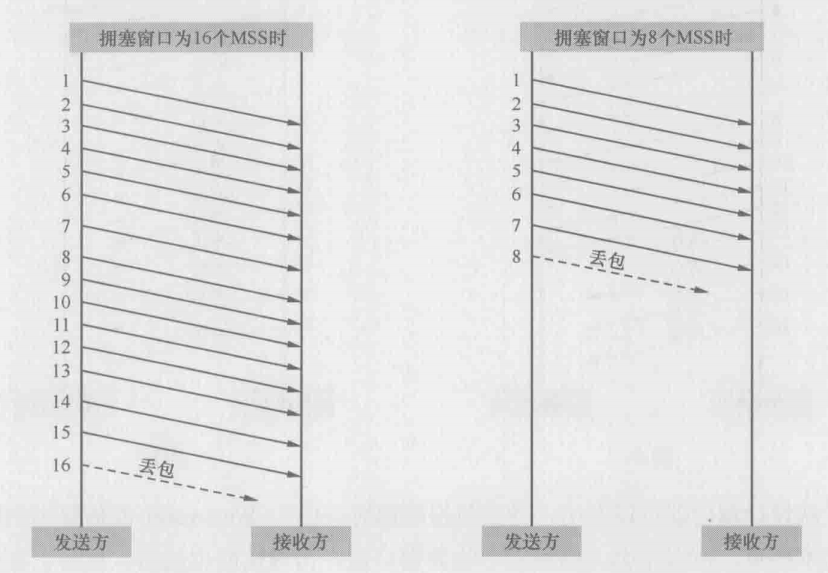
图1 图2
有些聪明人就不认同以上分析,比如有一位叫Saverio Mascolo 的意大利人看了这个算法之后,觉得太简单粗暴了,真实环境的丢包状况比上面的例子复杂得多,比如在相同大小的拥塞窗口中,有时候丢包的比例大,有时候丢包的比例小,统一按照拥塞窗口的一般取值是不理想的。我们可以看看下面这个例子
图3和图4在发生丢包时的拥塞窗口都是16个MSS,不过图3丢了4个包,而图5丢了12个。如果按照RFC 2001 的算法,两边的临界窗口值都应该被定义为16/2=8个MSS,这显然时不合理的,因为图3丢了4个包,图4丢了12个,说明当时图3的带宽很可能比图4的大,应该把临界窗口值设得比图4的大才对。归纳以下,理想的算法应该时先推算出有多少包已经被送达接收方,从而更精确的估算发生拥塞时的带宽,最后再依据带宽来确定新的拥塞窗口。那么如何知道哪些包被送达了呢?可以根据接收方回应的Ack来推算。于是不安分的Saverio先生依据这个理论提出了Westwood算法(当然实施起来不是上述地那么简单),后来又升级为Westwood+
图3 图4
从设计理念就可以看出,当丢包很轻微时,由于Westwood能估算出当时拥塞并不严重,所以不会大幅度减小临界窗口值,传输速度也能得以保持。在经常发生非拥塞性丢包地环境中(比如无线网络),Westwood最能体现出其优势。
Vegas
接下来我们说说Vegas算法。如果说Westwood只是对TCP进行了细节性的、改良性的优化,Vegas则引入了一个全新的理念。本书之前介绍过的所有算法,都是在丢包后才调节拥塞窗口的,Vegas却独辟蹊径,通过监控网络状态来调整发包速度,从而实现真正的“拥塞避免”。它的理论依据也并不复杂:当网络状况良好时,数据包的RTT(round-trip time 往返时间)比较稳定,这时候就可以增大拥塞窗口;当网络开始繁忙时,数据包开始排队,RTT就会变大,这时候就需要减小拥塞窗口了。该设计的最大优势在于,在拥塞真正发生之前,发送方已经能通过RTT预测到,并且通过减缓发送速度来避免丢包的发生
当环境中所有发送方都使用Veags时,总体传输情况时更稳定、更高效的,因为几乎没有丢包会发生。而当环境中存在Vegas和其他算法时,使用Vegas的发送方可能时性能最差的,因为它最早探测到网络繁忙,然后主动降低了自己的传输速度。这一让步可能就释放了网络的压力,从而避免其他发送方遭遇丢包。
Compound
windows操作系统中用到的Compound算法同时维持了两个拥塞窗口,其中一个类似Vegas,另一个类似RFC 2581,但真正起作用的时两者之和。所以说Compound走的是中庸之道,在保持谦让的前提下也不失进取
linux系统中的TCP算法
linux操作系统则在不同的内核版本中使用不同的默认TCP算法,比如linux kernels 2.6.18用到了BIC算法,而linux kernels 2.6.19则升级到了CUBIC算法。后者比前者的行为保守一些,因为在网络状况非常糟糕的状况下,保守一点的性能反而更好
简单的代价——UDP
前文提到过UDP无需连接,所以非常适合DNS查询。图1和图2时分别在基于UDP和TCP时执行DNS查询的两个包,前者明显更加直截了当,两个包就完成了
基于UDP的查询:
基于TCP的查询:

UDP为什么能如此直接呢?其实是因为它设计简单,想复杂起来都没办法
在UDP的协议头中,只有端口号、包长度和校验码等少量信息,总共就8个字节。小巧的头部给它带来了一些优点
1.由于UDP协议头长度还不到TCP头的一半,所以在同样大小的包里,UDP包携带的净数据比TCP包多一些
2.由于UDP没有Seq号和Ack号等概念,无法维持一个连接,所以省去了建立连接的负担。这个优势在DNS查询中体现得淋漓尽致
当然,简单得设计不一定是好事,更多的时候会带来问题
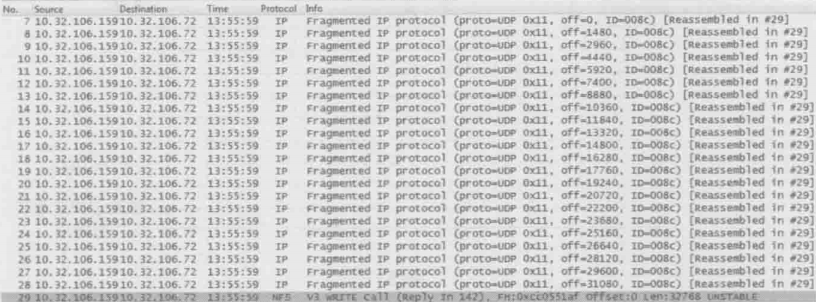
1.UDP不像TCP一样在乎双方MTU的大小。它拿到应用层让的数据之后,直接打上UDP头就交给下一层了。那么超过MTU的时候怎么办?在这种情况下,发送方的网络层负责分片,接受方收到分片后再组装起来,这个过程会消耗资源,降低性能。下图是一个32KB的写操作,根据发送方的MTU被切成了23个分片
2.UDP没有重传机制,所以丢包由应用层来处理。如下面的例子所示,某个写操作需要6个包完成,当基于UDP的写操作中有一个包丢失时,客户端不得不重传整个写操作(6个包)。相比之下,基于TCP的写操作就好很多,只要重传丢失的那1个包即可
基于UDP的NFS写操作:

基于TCP的NFS写操作:

3.分片机制存在弱点,会成为黑客的攻击目标。接受党之所以知道什么时候该把分片组装起来,是因为每个包里都有“More fragments”的flag。1表示后续还有分片,0则表示这是最后一个分片了,可以组装了。如果黑客持续快速德发送flag为1的UDP包,接收方一直无法把这些包组装起来,就有可能耗尽内存。下图左边时NFS写操作中7~28号分片的flag,右边时29号分片(最后一个分片)的flag

剖析CIFS协议
前文介绍过Sun设计的NFS文件共享协议,理论上NFS可以应用再任何操作系统上,但是因为历史原因,现实中只在linux/unix上流行。那windows上一般使用什么共享协议呢?它就是微软维护的SMB协议,也叫common internet file system(CIFS)。CIFS协议有三个版本:SMB、SMB2和SMB3,目前SMB和SMB2比较普遍
在windows上创建CIFS共享非常简单,只要在一个目录上右键单击,在弹出的菜单中选择属性–>共享,再配置一下权限就可以了。如下图所示,再其他电脑上只要输入IP和共享名就可以访问它了
CIFS在企业环境中应用非常广泛,比如映射网络盘或者共享打印机;同事间共享资料也可以采用这种方式
CIFS的工作方式
三次握手建立连接
客户端10.32.200.43打开共享文件\10.32.106.72\dest\abc.txt 时,底层究竟发生了什么?借助wireshark,我们可以把这个过程看的清清楚楚
首先,CIFS只能基于TCP,所以必定是以三次握手开始的。从下图可见,CIFS服务器上的端口号为445

Negotiate
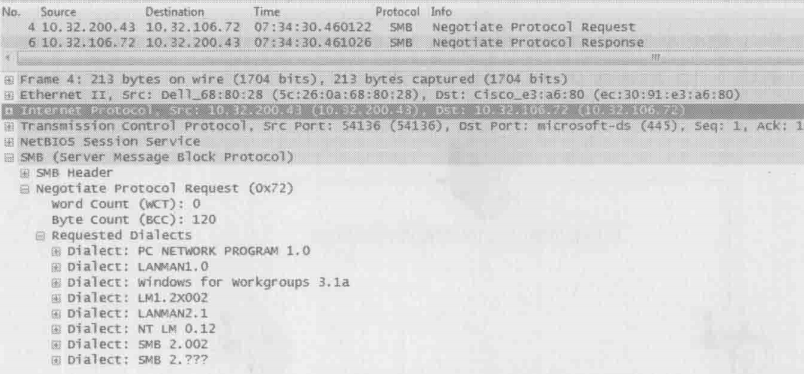
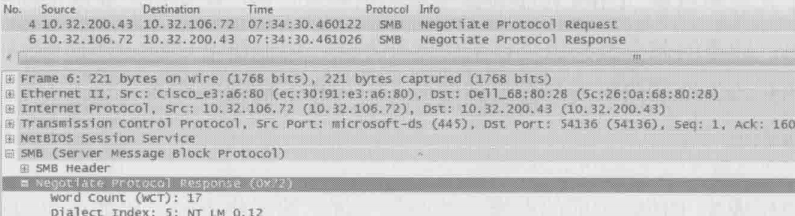
接下来的第一个CIFS操作是Negotiate(协商)。请关注下图的底部,可见客户端把自己支持的所有CIFS版本,比如SMB2和NT LM 0.12(为了便于和SMB2对比,接下来我们称它为SMB)等都发给服务器
服务器从中挑出自己所支持的最高版本回复给客户端。从下图中可知,服务器选择的是NT LM 0.12(SMB),这说明了该服务器不支持SMB2
CIFS Session
协商好版本之后,就可以建立CIFS Session了,如下图所示

Session Setup的主要任务是身份验证,常用的方式由Kerberos和NTLM(本例就是用到NTLM)。假如由用户抱怨访问不了CIFS服务器,问题很可能就发生在Session Setup
Tree Connect
Seesion Setup过后,意味着已经打开\10.32.106.72了,接下来要做的是打开\dest共享。如下图所示,这个操作称为Tree Connect
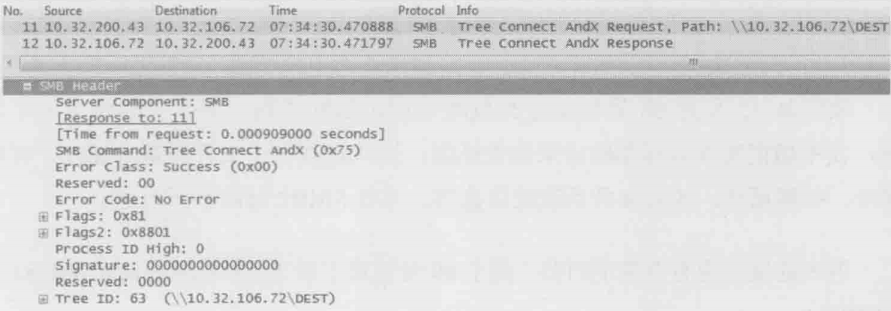
点开着两个Tree Connect包,最有价值的信息当属服务器返回的Tree ID(如上图底部所示)。从此之后客户端就能利用这个ID去访问/dest共享的子目录和子文件
Tree Connect有关问题
常见问题1:如果用户无权访问此目录,会不会在Tree Connect这一步失败?
不会。Tree Connect并不检查权限,所以即便是无权访问的用户也能得到Tree ID。检查权限的工作由接下来的Create操作完成
常见问题2:某用户已经打开了\10.32.106.72\dest\abc.txt,如果还想再打开\10.32.106.72\dest\abc.txt,需要再建一个TCP连接吗?
没有必要,在一个TCP连接上能维持多个打开的Tree Connect
Create
其实从13号到68号都是类似下图所示的网络包,下图只显示了一小部分。这些包查询了文件的基本属性、标准属性、扩展属性,还有文件系统的信息等
再多的属性也有查完的时候,到了69号包终于看到Create Request \abc.txt了

Create是CIFS中非常重要的一个操作。无论是新建文件、打开目录,还是读写文件,都需要Create。有时候我们因为没有权限遭遇“Access Denied”错误,或者覆盖文件时收到“File Already Exists”提醒,都是来自Create这个操作
Create有关问题
常见问题1:如果\dest 的权限里禁止某用户访问,但\dest\abc.txt 的权限里允许该用户访问,那他打开\10.32.106.72\dest\abc.txt 时会不会失败?
如果该用户先打开\10.32.106.72\dest,就会在“NT Create \dest”这一步收到Access Denied报错,当然就无法再进一步打开abc.txt了。而如果直接再地址栏输入\10.32.106.72\dest\abc.txt,则可以跳过“NT Create \dest”这一步,所以不会有任何报错。也就是说可以直接打开子文件abc.txt,却打不开上级文件夹\dest
常见问题2:windows的 Backup Operators组中的用户有权限备份所有文件,但不一定有权限读文件,那服务器是怎么知道一个用户是想备份还是想读的?
备份和读这两个行为的确非常相似,都是依靠Read操作来完成的。它们的不同点在于,备份的时候在Create请求中的“Backup Intent”设为1,而读的时候“Backup Intent”设为0(如下图所示)。服务器就是依靠Backup Intent来决定是否允许访问的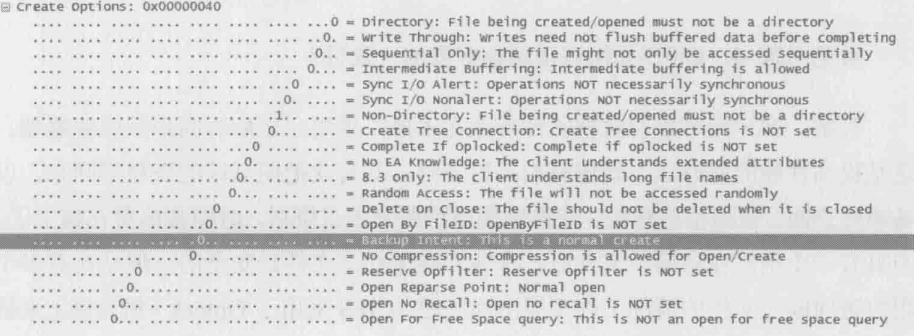
常见问题3:如果多个用户一起访问相同文件,CIFS如何处理冲突?
在Create请求中有Access Mask 和 Share Access Mask两个选项。前者表示该用户对此文件的访问方式(读、写、删等),后者表示该用户允许其他用户对此文件的访问方式。举个例子,用户A发送的Create请求中,Access Mask是“读+写”,Share Access Mask是“读”,表示自己要读和写,并同时允许其他人只读。假如接下来用户B也发送Access Mask是“读+写”的Create请求,就会收到“Sharing Violation”错误,因为A不允许其他人写
下图中的Access Mask只是读
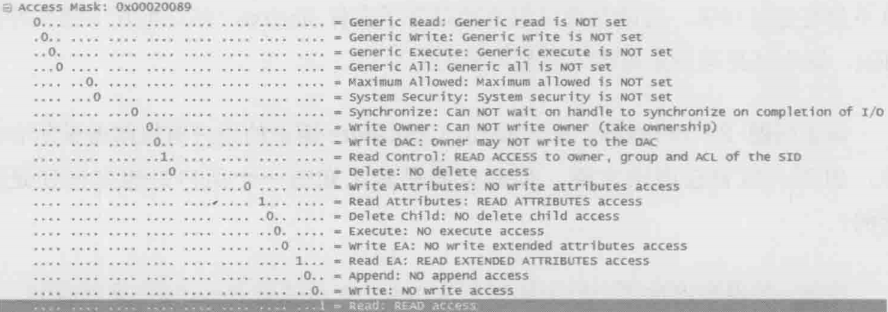
注意:这里讨论的访问冲突指的是CIFS协议层的,有些应用软件还有专门的机制防止访问冲突,比如Word和Excel,但Notepad就没有
Oplock 机会锁
常见问题4:CIFS如何保证缓存数据的一致性?
客户端可以暂时把文件缓存在本地,等用完之后再同步会服务器端,这是提高性能的好办法 。当只有一个用户在访问某文件时,客户端缓存该文件是安全的,但是再有多个用户访问同一文件的情况下则可能出现问题。CIFS采用了Oplock(机会锁)来解决这个问题。Oplock有Exclusive、Batch和Level 2 三种形式。Exclusive允许读写缓存,Btach允许所有操作的缓存,而Level 2 只允许读缓存。Oplock也是再Create中实现的,如下图底部所示,该客户端被授予Batch级别的机会锁,表示他可以缓存所有操作
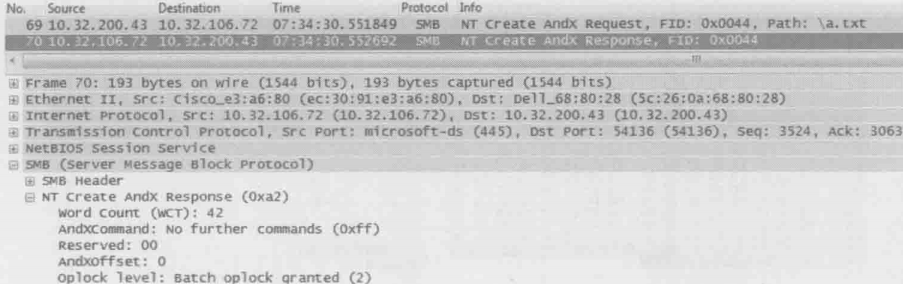
为了更好地理解Oplock地工作方式,我们假设一个场景来说明
1.用户A用Exclusive/Btach 锁打开某文件,然后缓存了很多修改地文件内容
2.用户B想读同一个文件,所以发了Create请求给服务器
3.如果此时服务器忽视A地Oplock,直接回复B地请求,那B就读不到被A修改后的内容(也就是出现数据不一致)。因此服务器通知A释放Exclusive/Batch 锁,换成Level2锁
4.A立即把缓存里的修改两同步到服务器上
5.服务器给B回复Create相应,同时授予其Level 2 锁。B接下来再发读请求,从而得到A修改后的文件内容
CIFS读行为
从71号包开始,读操作终于出现了。如下图所示,CIFS的都行为看上去和NFS非常相似,都是从某个offset开始读一定数量的字节。文件的内容“I need a vacation!”能从包里直接看出,说明传输时没有加密
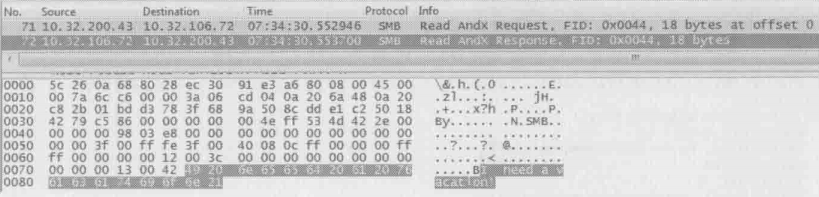
CIFS读行为有关问题
常见问题1:同样时用SMB协议读一个文件,windows XP和windows 7的表现有何不同?
windows XP的Request和Response是交替的
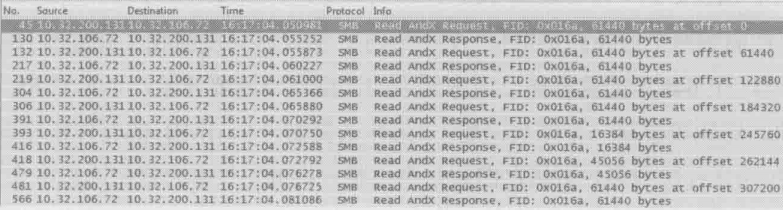
windows 7 的Requests是多个一起发出的
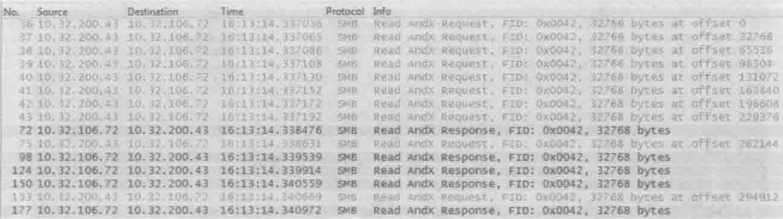
这两种读方式在延迟小的网络中体现不出差别,在带宽小的环境中差别也不大(因为发送窗口小,一个读请求本来就要多个往返次才能传完)。但在高延迟、大带宽的环境中就很不一样了,windows 7 的性能会比windows XP好很多。在网络有丢包的情况下差别还会更大,因为windows XP 比windows 7更容易碰到超时重传
常见问题2:利用windows explorer从CIFS共享上复制文件,为什么比Robocopy和EMCopy之类的工具慢很多?
如果复制一个大文件可能是看不出差别的,但如果是复制一个包含大量小文件的目录,的确是比这些工具慢很多,这是因为windows explorer是逐个文件复制的(单线程),而这些工具就能同时复制多个文件(多线程)
单线程的复制:

多线程的复制:
常见问题3:从CIFS共享里复制一个文件,然后粘贴到同一个目录里,为什么还不如粘贴到客户端的本地硬盘快?
前者需要把数据从服务器复制到客户端的内存里,然后再从客户端的内存写到服务器上,相当于读+写两个操作。而后者只是从服务器读到客户端内存里,然后写到本地硬盘,相当于网络上只有读操作,这样就快了一些

SMB3对此有了本质上的改进,可以完全实现服务器端的本地复制,这样前者反而比后者快了
常见问题4:在CIFS共享上剪切一个文件,然后粘贴到同一共享的子目录里,为什么就比粘贴到本地硬盘快呢?
在相同的文件系统上剪切、粘贴,本质上只有“rename”操作,并没有读和写,所以是非常快的。请看下图的抓包,该操作是把abc.txt剪切到一个叫\test的子目录
常见问题5:为什么在windows 7 上启用SMB2之后,读性能高了很多?
这是因为SMB2没有SMB那么啰嗦。从下图可见,都之前的查询用了不到10个包,而SMB往往要用数十个包来查询各种信息

网络江湖
COMPUND CALL(复合请求)
早期CIFS协议的设计比NFS落后不少,甚至可以看到一些“不专业”的痕迹
1.早期CIFS协议非常啰嗦
2.早期CIFS协议的读写操作都是同步方式的
如下图所示,它只会在收到上一个读响应(Read Andx Response)之后,才发出下一个读请求(Read Andx Request)。这种方式的带宽利用率很低,因为很可能TCP发送窗口还没有用完,一个操作就完成了。CIFS的设计人员当时可能没有考虑到网络带宽的快速发展
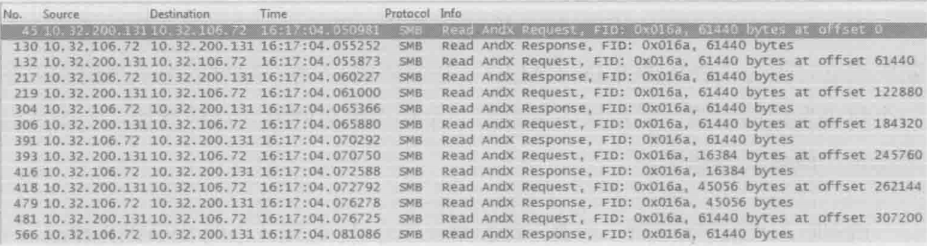
早期的NFS上就没有这个问题,如下图所示,多个读请求被一起发出去了(也可以说是异步的)

当然早期的NFS协议也有落后的地方,比如对文件属性的管理过于简单
即使不太啰嗦的NFS协议在读一个文件之前,也需要通过READDIRPLUS操作获得其File Handle(FH),再通过GETATTR操作获得该File Handle的属性,最后通过ACCESS和READ操作打开文件。下图显示了READ之前的三个操作至少花费了三个RTT(往返时间)
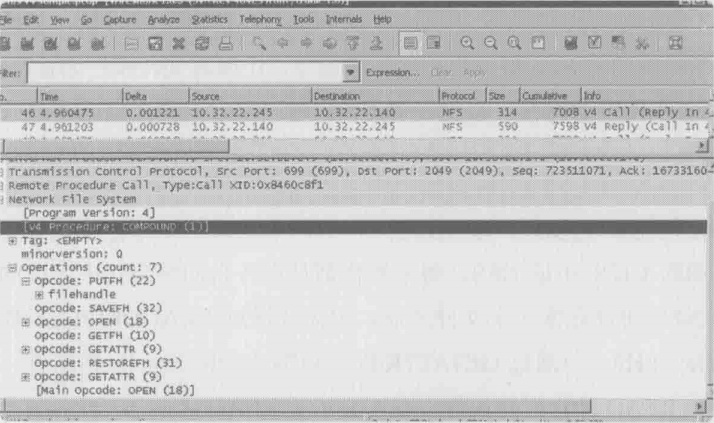
NFSv4中又提出了一个全新的理念,称为**“COMPUND CALL”(复合请求)**。客户端可以把多个请求放在一个包中发给服务器,然后服务器也在一个包中集中回复,这样就能在一个往返时间里完成多项操作了
道理听起来似乎很简单,但真正做起来并不容易。以上图中的READDIRPLUS+GETATTR+ACCESS+READ为例,如果用COMPUND方式,发送方在没有收到READDIRPLUS回复之前,怎么知道GETATTR操作应该指定什么File Handle呢?NFSv4用了类似变成时用到的“变量”思维来实现,首先是READDIRPLUS操作所得到的File Handle被作为变量传给GETATTR请求;接着GETATTR操作得到的文件属性又传给ACCESS和READ。变量的传递完全发生在服务器端,所以客户端不需要参与,也就没有来回发包的需要
下图时一个包含了7个操作请求的NFSv4八篇,COMPUND方式对效率的提高幅度由此可见一斑
Offload Date Transfer
SMB3也出现了很多适应当前需求的革命性创新
当通过CIFS复制abc.txt,然后粘贴到同一目录生成abc-Copy.txt时,网络包如下所示

说明复制粘贴的过程实际是这样的:
1.客户端发送读请求给服务器
2.服务器把文件内容回复给客户端(这些文件内容被暂时存在客户端内存中)
3.客户端把内存中的文件内容写道服务器上的新文件abc-Copy.txt中
4.服务器确认写操作完成
在这个过程中,问年内容通过第2步和第3步在网络上来回跑了两次,是很浪费带宽资源的,为此SMB3设计了一个叫**“Offload Data Transfer”的功能**,能够把过程变成这样:
1.客户端向服务器发送复制请求
2.服务器给了客户端一张token
3.客户端利用这张token给服务器发写请求
4.服务器按要求写新文件
5.服务器告诉客户端复制已经完成
下图显示了这两种复制方式的差别,实心箭头表示文件内容的流向
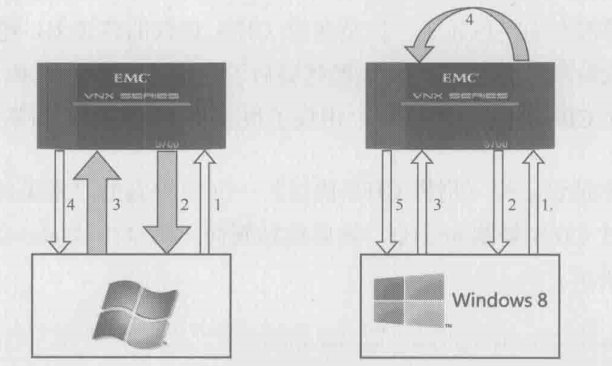
可见在SMB3的复制过程中,我们只是在网络上传输了一些指令,而文件内容并没有出现在网络上,因为复制数据包完全由服务器自己完成了。假如是复制一个大文件,那对性能的提升幅度是非常可观的,你甚至可以在数秒钟里复制几个GB的数据,远超网络的瓶颈。在虚拟化的应用场合中,通过这个机制克隆一台虚拟机也可以变得很快
负载均衡
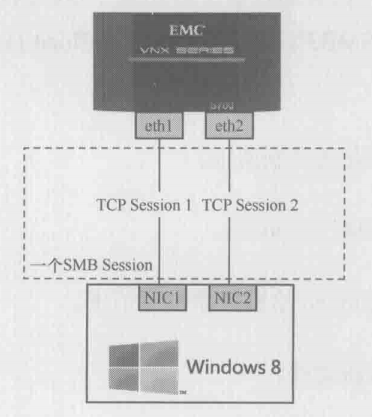
SMB3的另一个破天荒改进是在CIFS层实现了负载均衡。与其他CIFS版本不同,一个SMB3 Session可以基于多个TCP连接。如下图所示,windows 8 服务器上的两个网卡,可以分别和文件服务器上的两个网卡建立TCP连接,然后一个SMB3 Session就基于这两个连接之上。当其中一个TCP连接出现故障,比如网卡坏掉时,SMB3连接还可以继续存在
BranchCache
考虑到现在全球化的大公司越来越多,有了很多总部和分部,所以远距离的文件传输就成了大问题。比如说,中国总部的机房中存在一个大文件,从澳大利亚分部访问该文件是非常慢的。尤其是当分部中有很多用户需要访问同一个文件时,相同的内容就需要在有限的带宽中传输多次。SMB3提出了一个叫BranchCache的机制来解决这个问题。当澳大利亚分部的第一个用户访问该文件时,文件从中国传输过去,然后就被缓存起来(比如存到分部的专用服务器上)。接下来澳大利亚分部如果有其他用户访问该文件,就可以通过文件签名从缓存服务器上找到了
Countinuous Availability
以前很多厂商的文件服务器号称支持Active/Standby(当前待机)模式,即文件服务器的两个机头共享硬盘,当一个机头宕机时,能即使切换到待机的机头上。“即时”这个词实际上是由虚假宣传嫌疑的,因为SMB3之前的CIFS版本把文件锁之类的信息放在机头的内存中,新的机头起来时无法获得这些信息,所以是没办法无缝地提供访问的,必须让客户端重新访问一次
SMB3对此地解决方案是把文件锁之类的信息存到硬盘上,所以新机头起来时便可以获得这些信息,这样,提供无缝服务就成了一种可能
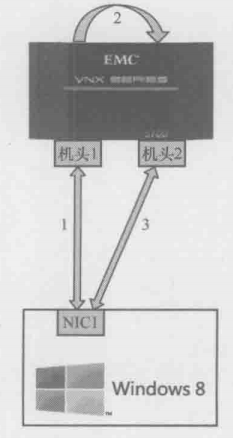
1.windows 8 客户端通过机头1访问文件,生成的文件锁等信息被保存在硬盘中
2.机头1发生故障,切换到机头2上,机头2从硬盘中获取信息
3.windows 8 仍然能锁定该文件,因为机头2继承了机头的信息
注:“机头”指的是文件服务器的控制器节点(Controller Node)或服务器节点(Server Node),具体来说,是指具备独立 CPU、内存、网络接口,并能独立运行文件服务协议(如 SMB/CIFS)的硬件或逻辑单元
DNS小科普
DNS的基本功能
A记录
在浏览器上输入一个域名时,比如www.example.com,其实不是根据该域名直接找到服务器,而是**先用DNS解析成IP地址,再通过IP地址找到服务器**。**有时候甚至不用输入任何域名,也会在不知不觉中用到DNS。比如打开公司电脑**,用域账号登录操作系统,就是依靠NDS找到Domain Controller来验证身份。毫不夸张得说,如果有一天突然失去DNS,世界会立即陷入混乱
作者得笔记本IP为192.168.1.101,DNS服务器IP为106.186.28.239。如果在打开www.example的过程中抓了包,就能看到下图所示的解析过程

笔记本:“请问www.example.com的A记录是什么?”
服务器:“是93.184.216.119”
获得IP之后,笔记本就可以和93.184.216.119建立HTTP连接了。这个例子中提到的A(Address)记录,指的是从域名解析到IP地址
PTR记录(Pointer Record,指针记录)
与A记录的功能相反,它能从IP地址解析到域名。PTR有什么作用呢?比如IT部门发现最近公司里的机器10.32.106.47和YouTube之前的数据流量很大,用nslookup一查PTR记录就知道原来是作者在上班时间偷看视频了
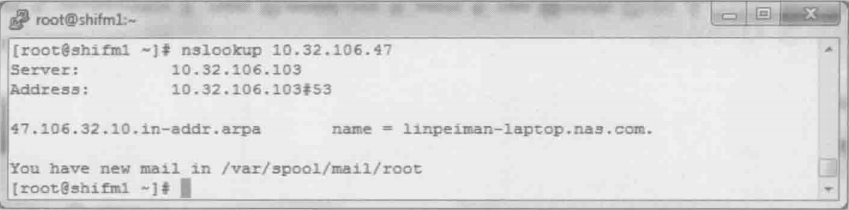
网络包显示如下:
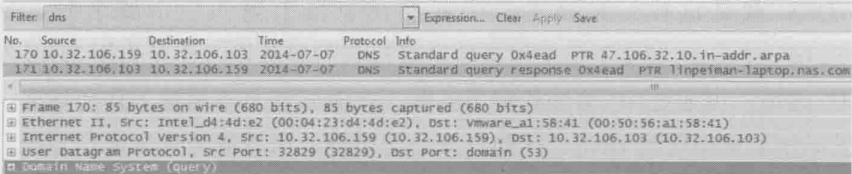
SRV记录(Service Record,服务定位记录)
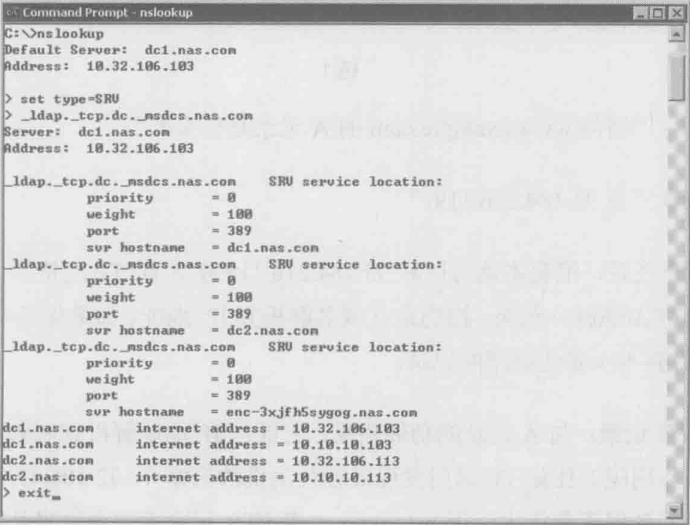
windows的域管理员要特别关心SRV记录,因为它指向域里的资源。比如想知道作者公司的域nas.com里有哪些DC,只要随便在一台电脑上查询_ldap._tcp.dc._msdcs.nas.com这个SRV记录就可以了。如果你想查贵司的DC,请把nas.com改成正确域名即可。下图是查询过程的截图
CNAME记录
又称为Alias记录,就是别名的意思。比如作者的服务器10.32.106.73同时提供网页(www)、邮件(mail)和地图(map)服务。下图是该服务器在DNS中的配置,其中ww的A记录指向了10.32.106.73,还有两个别名记录mail和map指向了www。客户端访问这3个域名是,都会被定向到10.32.106.73上面
别名是如何起作用的呢?当客户端查询mail.nas.com或者map.nas.com时,DNS服务器通过www.nas.com找到10.32.106.73,然后把结果返回给客户端。下图是访问mail.nas.com时抓的包

那直接把10.32.106.73配给mail和map可以吗?当然时可以的,但如果某天要改变这个IP地址,就不得不在DNS上修改www、mail和、map这3项记录了。而在使用别名的情况下,只要修改www一项的IP就行了,mail和map都没有必要改动。别名的使用节省了管理时间
DNS的工作方式
递归查询
上文DNS服务器成功解析了www.example.com,这种工作方式称为递归查询,其特点时客户端完全依赖服务器直接返回结果
迭代查询
除了递归查询之外,还有一种叫迭代查询的方式,其特点时客户端先查到根服务器的地址,再从根服务器查到权威服务器,然后从权威服务器查……直到返回想要的结果。用dig命令加上“+trace”参数可以强迫客户端采用迭代查询。下雨就是查询的整个过程,可见迭代查询比递归查询麻烦地多,但最后解析地结果倒是一致的
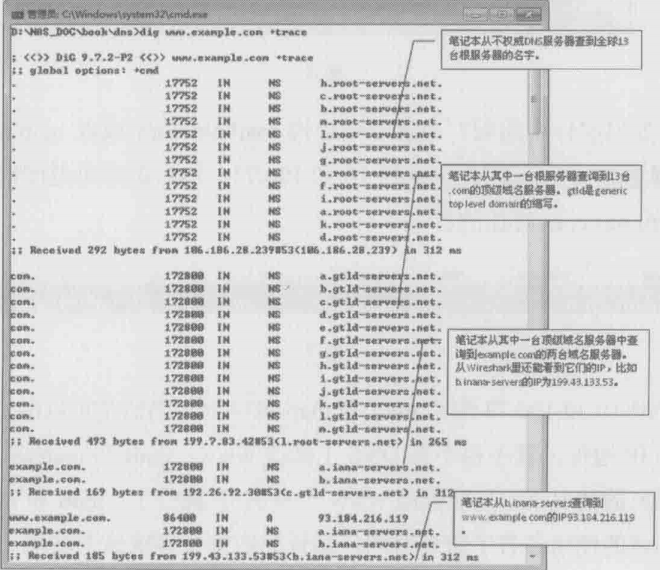
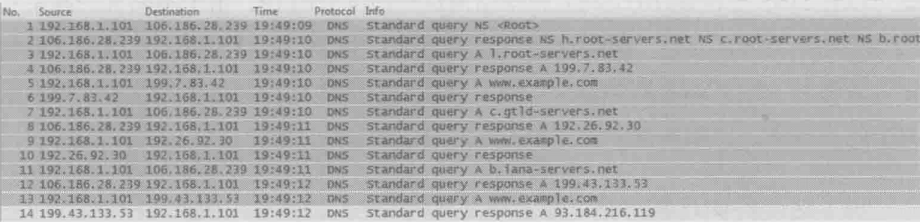
这个迭代查询地网络包如下图所示。从中可以看到笔记本192.168.1.101发出了7个查询,才得到最终的结果
DNS循环工作(round-robin)模式
作者的DNS中有两个叫“Isilon-Cluster”的同名A记录,分别对应着IP地址10.32.106.51和10.32.106.52。当作者连续执行两次“nslookup Isilon-Cluster.nas.com”时,在抓到的网络包如下图所示

可见两次返回的IP地址是一样的,但顺序却是相反的。如果执行第三次nslookup,结果又会跟第一次一样,这就是DNS的循环工作(round-robin)模式。这个特性可以广泛用于负载均衡。比如某个网站有10台Web服务器,管理员就可以再DNS里创建10个同名记录指向这些服务器的IP。由于不同客户端查到的结果顺序不同,而且一般会选用结果中的第一个IP,所以大量客户端就会被均衡地分配到10台Web服务器上。
DNS的缺点
1.DNS上存在山寨域名。比如招商银行的域名是www.cmbchina.com,但是www.cmbchina.com.cn和www.cmbchina.cn却不一定属于招行。如果这两个域名被指向外表和招行一样的钓鱼网站,就可能骗到部分用户的银行账号和密码
2.如果DNS服务器被恶意修改也是很危险的事情。比如登录招行网站时虽然用了正确域名www.cmbchina.com,但由于DNS服务器是黑客控制的,很可能解析到一个钓鱼网站的IP
3.即便是配了正规的DNS服务器,也是有可能中招的。比如**正规的DNS服务器遭遇缓冲投毒(向DNS服务器的缓存中注入虚假的域名解析记录)**之后,也会变得不可信
4.DNS除了能用来欺骗,还能当作攻击性武器。著名的DNS放大攻击就很让人头疼。下面是作者再执行“dig ANY isc.org”(解析isc.org的所有信息)时抓的包,可见6号包发出去的请求只有25字节(见图1底部的Length:25),而11号包收到的回复却能达到3111字节(见图2底部的Length:3111),竟然放大了124倍
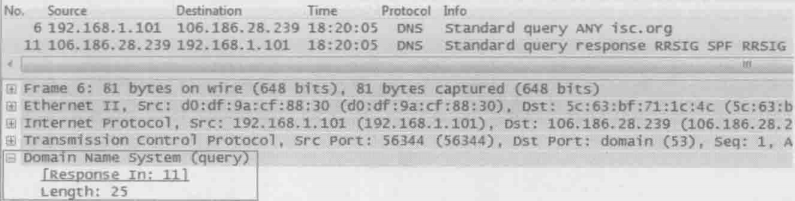
图1
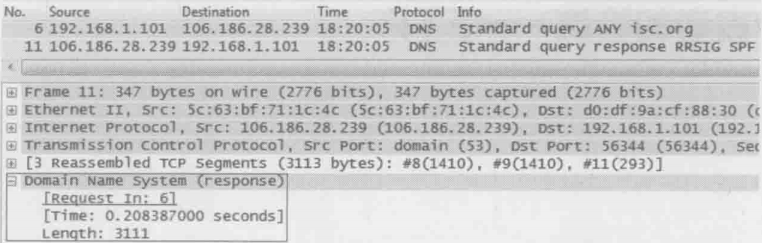
图2
假如在6号包里伪造一个想要攻击的源地址,那该地址就会莫名收到DNS服务器3111字节的回复。利用这个放大效应,黑客只要控制少量电脑就能把一个大网站拖垮了
一个古老的协议——FTP
FTP的过人之处,就在于它用最简单的方式实现了文件的传输——客户端只需要输入用户名和密码,就可以和服务器互传文件了;有的甚至连用户名和密码都不用(匿名FTP)。FTP常被用来传播文件,尤其时免费软件;另一个广泛应用是采集日志,我们可以让服务器发生故障之后,自动通过FTP把日志传回厂商。这些场合之所以适合FTP而不是NFS或者CIFS,就是因为它实现起来更加简单
FTP的控制连接和数据连接
作者从windows客户端登录了一次FTP服务器,然后下载了一个叫linpeiman.txt的文件。我们先来看看登录的过程(见下图)
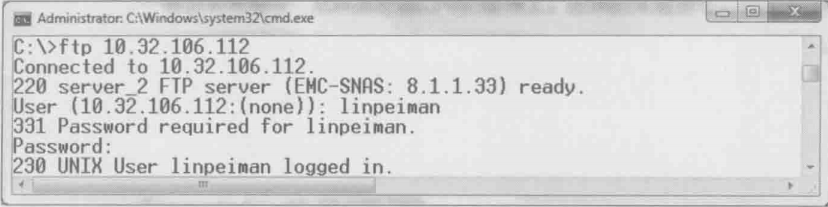
接下来看看登录过程的网络包,前三个包无需解析(见下图),就是有客户端发起的三次握手。唯一值得记住的是FTP服务器的控制端口21

现在来分析5、7、8、10、11号包的过程

5号包:
服务器:“我准备好接收访问啦,顺便说一下我是一台EMC公司的存储,版本号8.1.1.33”
7号包:
客户端:“我想以用户名linpeiman登录”
8号包:
服务器:“那你把linpeiman的密码告诉我”
10号包:
客户端:“密码是123456”
11号包:
服务器:“密码正确,linpeiman登录成功”
从以上分析可见,FTP是用明文传输的,连作者的密码123456都可以被Wireshark解析出来。如果对安全的要求非常高,就不能采用这种方式。接下来再看下载文件的过程
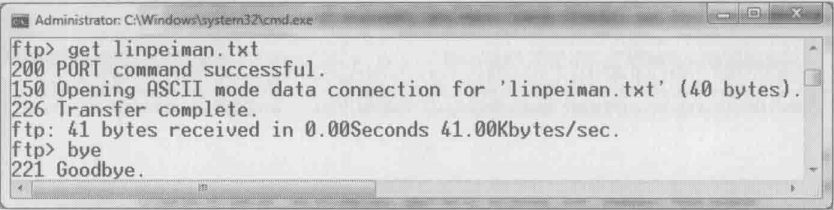
现在分析下载过程的网络包

13号包:
客户端:“我想从IP=10.32.200.41,端口为208*256+185=53433 连接你的数据端口(公式中的256为约定好的常数)”
14号包:
服务器:“可以的,我同意了”
15号包:
客户端:“那我想下载文件linpeiman.txt”
22号包:
服务器:“给你传了”
上面这些包并没有真正传输文件内容,我们接着看
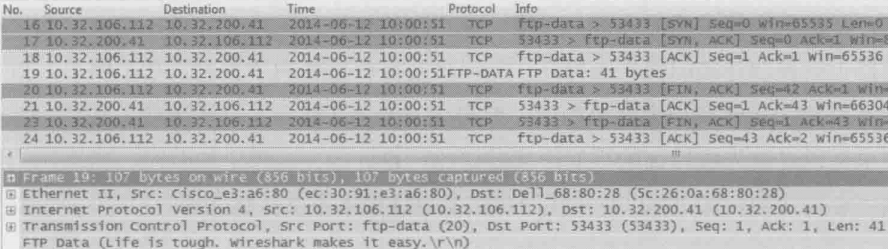
16、17、18号包也是三次握手,不过这次发起者是FTP服务器。服务器的端口采用了20,客户端的端口则为之前协商好的53433
19号包:
服务器:“给你文件内容(文件内容“Life is tough.Wireshark makes it easy.”可见于上图的底部)”
20、21、23、24号包为四次挥手过程,表示数据传输结束,TCP连接关闭了
从以上分析可见,客户端连接FTP服务器的21端口仅仅是为了传输控制信息,我们称之为“控制连接”。当需要传输数据时,就重新建立一个TCP连接,我们称之为“数据连接”。随着文件传输结束,这个数据连接就自动关闭了。不但在下载文件时如此,就连执行ls命令来列举文件时,也需要新建一个数据连接。这不是一种高效的方式,因为三次握手和四次挥手就用掉7个包。而ls命令的请求和响应往往只需要2个包。
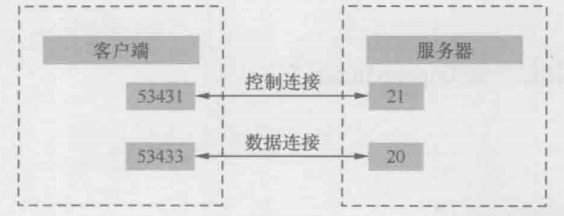
作者唯一想到把控制连接和数据连接分开的好处是连接分开后,就有机会在路由器上把控制连接的优先级提高,免得数据传输影响了控制。举个例子,当文件下载到一半是我们突然反悔了,就可以Abort(终止)这次下载。如果Abort请求时通过优先级较高的控制连接发送的,也许能完成得更加及时。当然作者认为他的猜测可能是错的,20世纪70年代得路由器也许根本不支持优先级
FTP被动模式
如果你为FTP配置过防火墙,还会发现这种方式带来了一个更加严重的问题——**由于数据连接的三次握手是由服务器端主动发起(我们称之为主动模式),如果客户端的防火墙阻挡了连接请求,传输不就失败了吗?**碰到这种情况时,作者建议试一下FTP的被动模式。下图是在被动模式下抓到的包。由于被动模式的登录过程和主动模式一样,所以我们从登录之后开始讲起

24号包:
客户端:“我想用被动模式传输数据”
25号包:
服务器:“你可以连接到IP=10.32.106.112,端口号为240*256+217=61657(公式中的256为约定好的常数)”
29号包:
客户端:“我想下载linpeiman.txt”
30号包:
服务器:“给你传了”
上面这些包并没有真正传输文件内容,我们接着看
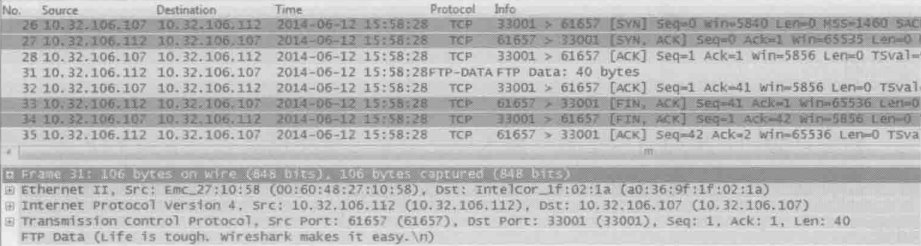
26、27、28号包是数据连接的三次握手,可见这一次由客户端主动发起(所以对于服务器来说是被动的),连接的服务器端口为之前协商好的61557
31、32、33、34、35号包完成了文件内容的传输,然后关闭数据连接。同样从下图底部可以见到该文件的内容:Life is tough.Wireshark makes it easy
最后作者在FTP命令行中打了个“bye”命令

Goodbye过程的网络包如下图所示

39号包:
客户端:“我要退出啦”
40号包:
服务器:“好的,Goodbye!”(FTP是作者所知道的最讲礼仪的协议)
41、42、43、44号包是四次挥手过程,断开控制连接,完成了一次FTP的生命周期
也许你想问,那如何指定客户端采用主动还是被动模式呢?很多FTP客户端软件都有这个选项。比如下图是WinSCP上的截图,选中Passive mode即表示被动模式
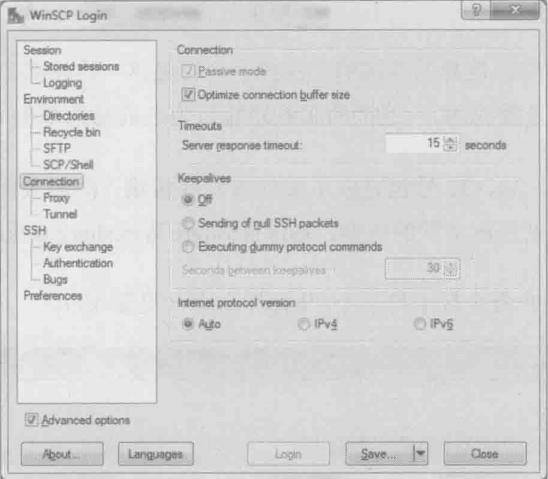
理论上所有FTP客户端都应该支持这两种模式,但Windows自带的ftp命令似乎只支持主动模式。下图是作者试图采用被动模式的命令
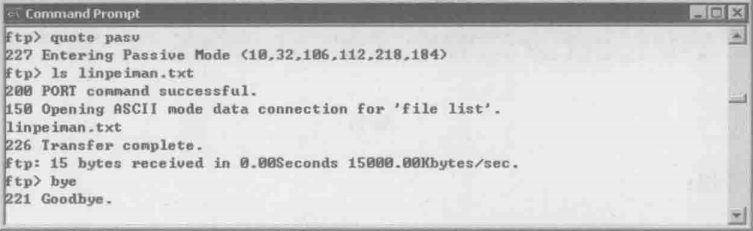
从上图中看,当输入“quote pasv”命令时,的确显示进入被动模式(Entering Passive Mode)。接下来我们看看下图的网络包。12号包和13号包也的确显示进入被动模式,但是接下来的网络包却完全时主动模式的样子
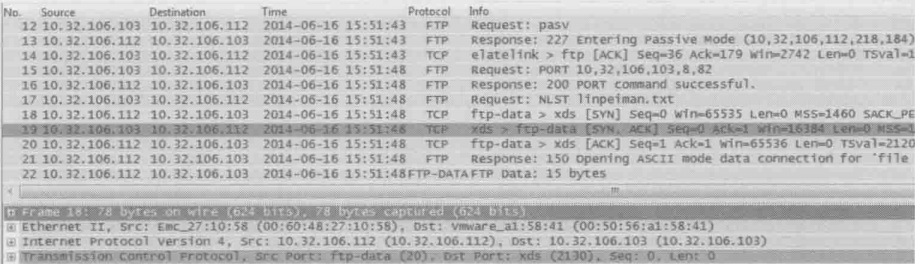
从结果看,12号包和13号包完全没有起作用,这很可能是windows的一个bug
上网的学问——HTTP
HTTP的工作方式
HTTP的工作方式算不上复杂,先由客户端向服务器发起一个请求,再由服务器回复一个响应。根据不同需要,客户端发送的请求会用到不同方法,有GET、POST、PUT、HEAD等。比如再网站上登录账号时就可能用到POST方法
作者再打开网页http://www.rfc-editor.org/info/rfc2616 时抓了包,我们就以此为例,来看看HTTP是如何工作的

1.由于HTTP协议基于TCP,所以上来就是三次握手。从上图的底部可以看到,服务器的端口号为80
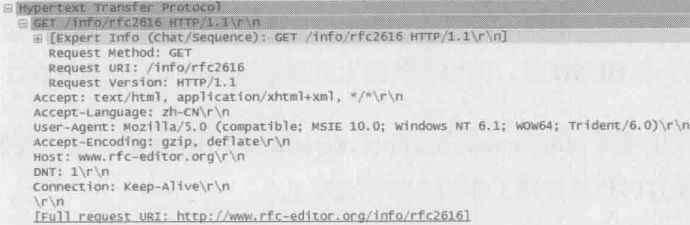
2.再下图中,4号包是客户端向服务器发送的“GET /info/rfc2616 HTTP1.1”请求,即通过1.1版的HTTP协议,获取/info 目录里的rfc2616文件。说白了就是向下载页面内容

3,7号包是服务器对该请求的响应,即把/info/rfc2616 的内容发给客户端
4.9号包是客户端向服务器请求“GET /style/rfc-editor.css”。该css文件定义了页面的格式
5.11号包是服务器对该请求的响应,把/style/rfc-editor.css 的内容发给客户端
就这样,客户端通过两个GET方法得到了页面内容和格式,从而打开了网页。如果点开每一个HTTP包前的+号,还能看到其协议头和详细信息。以4号包为例,它的HTTP协议头再Wireshark中如下图所示,其包含的信息大概可以归纳为:我要通过1.1版的HTTP协议,从服务器www.rfc-editor.org 的/info目录里得到 rfc2616的内容
HTTP算不上一个复杂的协议,出问题的时候也能在浏览器上看到错误信息,所以我们用到Wireshark的机会不多。不过随着技术的进步,HTTP越来越多地应用到不需要浏览器地场景中,比如现在如火如荼地云存储技术就有Wireshark地用武之地
由于海量文件不适合传统的目录结构,所以云存储一般使用对象存储的方式——客户端访问文件时并不使用其路径和文件名,而是使用它的对象ID。身份验证也是通过HTTP协议实现的。工程师们处理此类问题时就能用上Wireshark了。下图时Wireshark解析后的HTTP读文件过程(只要在Wireshark上右键点击一个包,在弹出的菜单中选择“Follow TCP Stream”就可以打开这个窗口)。我们可以从中看到该文件的对象ID“59J5T5KV78EPOe7AJIV55UO93DVG4140QGQQ000ED7PR8EJH3OGUV”,还有身份验证时用到的用户名“paddy”和加密后的密码。我们甚至可以看到服务器回复的文件内容“I am Paddy Lin.”在这个过程中一旦发生问题,比如身份验证错了,就能从Wireshark看到
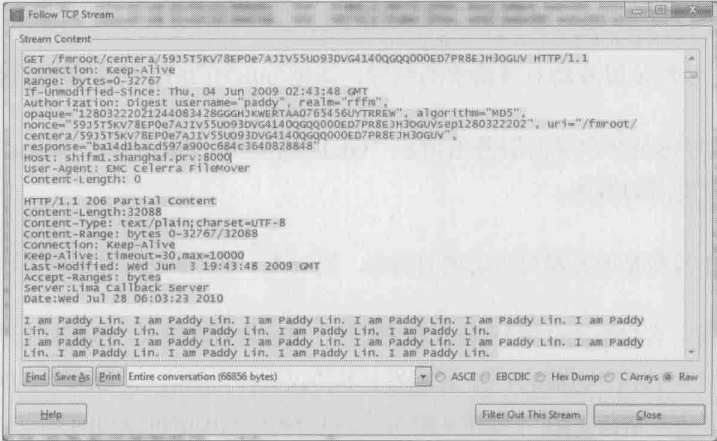
HTTPS
用Wireshark来解决HTTP问题是很痛快,因为整个通信过程一览无遗。但仔细一想却让人直冒冷汗——如果连传输的文件内容都可以清楚地看到,呢我上网时的聊天记录,甚至密码是否也会被发现?答案是肯定的。当客户端用POST方法把用户名和密码传给服务器时,已经在网络上暴露了身份
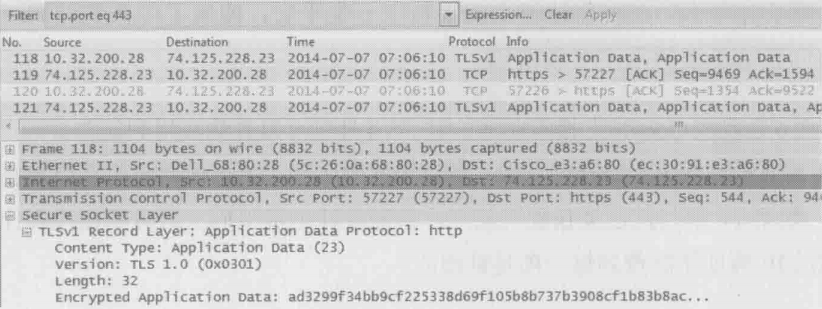
那要如何保护自己的信息呢?HTTPS就是一个不错的选择。下图就是使用HTTPS搜索时抓的包,注意服务器端口是443,关键词也被加密到了“Encrypted Application Data”里
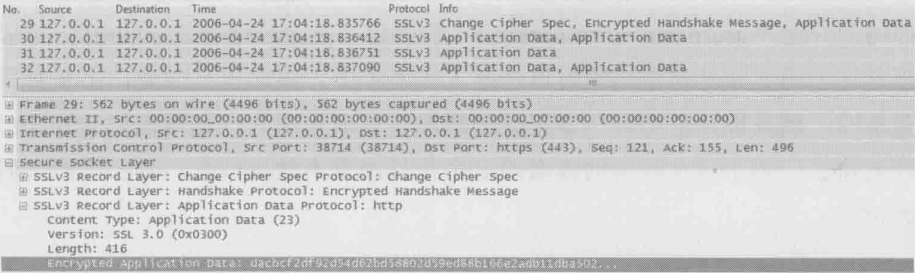
因为加密包会给诊断问题带来不少障碍,所以管理员有必要知道如何对它进行解码。下图是4个HTTP包,我们除了能看到“Application Data Protocol”是HTTP之外,几乎对它们一无所知,因为所有信息都被加密了
HTTPS信息解码
要对这些加密包进行解码,只需要以下几个步骤(本例所用的网络包和密钥来自http://wiki.wireshark.org/SSL 上的 snakeoil2_070531.tgz 文件,该网站现在已经打不开了)
1.解压snakeoil2_070531.tgz并记住key文件的位置
2.用Wireshark打开rsasnakeoil2.cap
单机Wiresahrk的Edit–>Preferences–>Protocols–>TLS–>RSA keys list
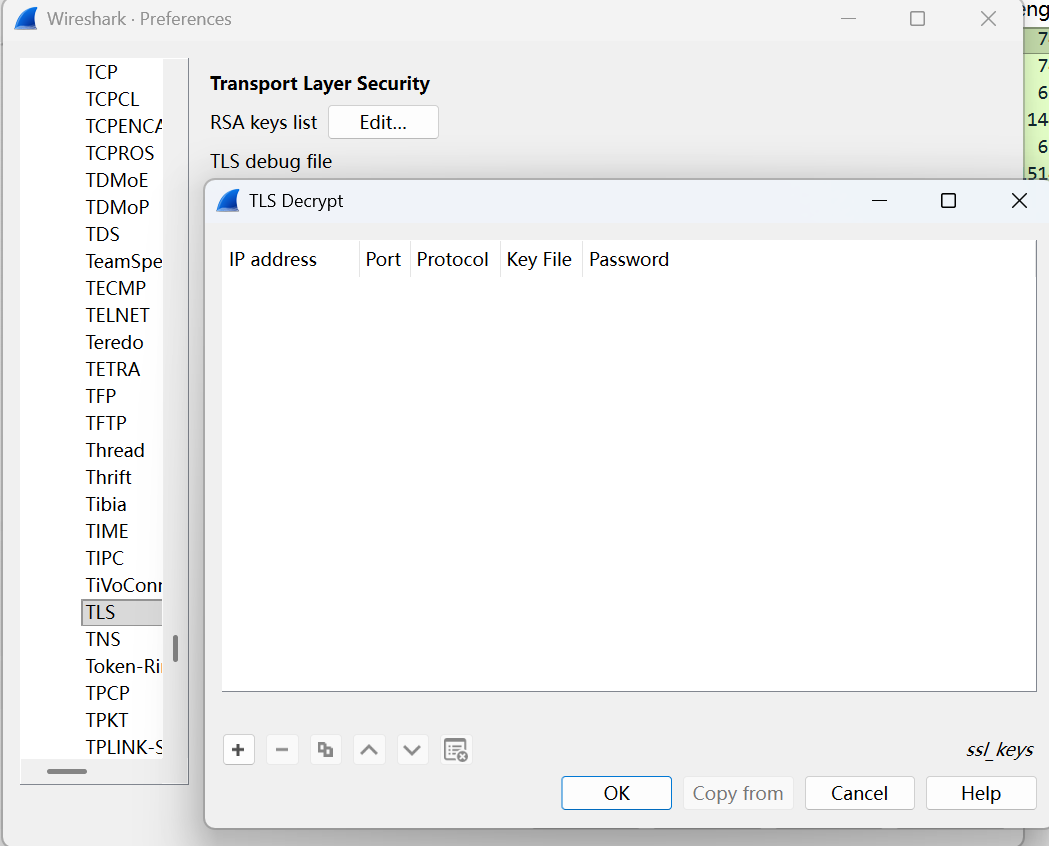

4.单机ok,这些包就成功解码了。下图就是这4个包解码后的样子,两个GET方法都可以看到
既然HTTPS包能被解码,是不是说明它也不安全呢?事实并非如此,因为解码所用到的密钥只能在服务器端导出
无懈可击的Kerberos
本文要介绍的身份认证协议叫Kerberos,它有着非常广泛的应用,比如windows域环境的身份认证就会用到它。我们用域账号登录电脑,就在不知不觉间完成了一次Kerberos认证过程
Kerberos的认证结果是双向的——当账号A访问资源B时,不但B要确保A并非冒充,而且A也要查明B不是假货。我们一般只知道前者,比如前文提到的CIFS服务器就要在Session Setup中对造访者验明正身。后者则很少被提及,因为人们一般不会怀疑自己要访问的资源时假的,其实后者还是很有必要的
双向认证的方式不止一种,最简单的做法是互报密码。这种方式的弊端很多,最大的问题是不方便管理。比如在一个数百名员工共享几百台机器的环境中,当新加入一名员工时,就得在几百台机器上更新账号信息。
Kerberos采用的方法是引入一个权威的第三方来负责身份认证。这个第三方称为KDC,它知道域里所有账号和资源的密码。加入账号A要访问资源B,只要把KDC拉出来证明双方身份就行了。在这种机制下,A和B都没必要知道对方的密码,完全依赖KDC就可以
在下面的实验中,账号A是作者的域账号linpl,资源B是一台叫CAVA的windows服务器。账号A访问资源B其实就是linpl登录CAVA的过程
第一步,账号A和KDC互相认证
1.账号A利用hash函数把密码转化成一把密钥,我们称它为Kclt
2.用Kclt把当前时间戳加密,生成一个字符串。我们用“{时间戳}Kclt”来表示它
3.把上一步生成的字符串“{时间戳}Kclt”、账号A的信息,以及一段随机字符串发给KDC。这样就组成了Kerberos的身份认证请求AS_REQ
AS_REQ = “{时间戳}Kclt”,“账号A的信息”,“随机字符串”
如下图所示,作者实验室中的账户名字为linpl,本次生成的随机字符串是136224786
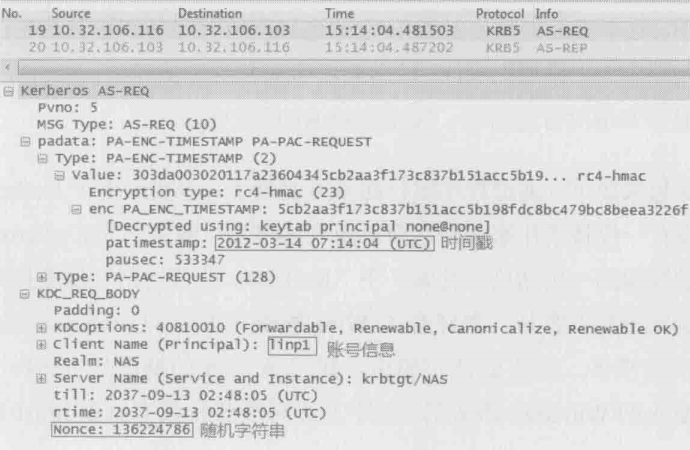
4.KDC收到AS_REQ之后,先读到账号A的信息“linpl”,于是便调出A的密码,再用同样的hash函数转化为Kclt。有了Kclt就可以解开“{时间戳}Kclt”了,如果能解开则说明该请求是由账号A生成的,因为其他账号不可能有Kclt可以加密
Kerberos为什么要选用时间戳来加密,而不是其他呢?原因就是黑客可能在网络上截获字符串“{时间戳}Kclt”,然后伪装成账户A来骗认证。这种方式称为重放攻击。重放攻击的伪装过程需要一段时间,所以KDC把解密得到的时间戳和当前时间作对比,如果相差过大就可以判断是重放攻击了。假如采用域时间无关的字符来加密,则无法避开重放攻击,这就是我们必须在域中同步所有机器时间的原因
5.接下来轮到KDC向账号A证明自己的身份了,上文提到的随机字符串就用在这里。理论上KDC只要用Kclt加密随机字符串,再回复给账号A就可以证明自己的身份了。因为假的KDC是没有Kclt的,账户A拿到回复之后解不出那个随机字符串,就知道KDC有假
总结以上过程,账号A和KDC都没有向对方发送密码,所以即便一方是假的也不会泄露信息。而如果双方都是真的,则实现了互相认证,可以算是完美了。不过这个机制下的KDC会非常忙碌,假设每次认证都得调出账号密码、hash、解密……而且每个客户端一天可能要验证数十次,那域中就得配备大量的KDC才负担得起。Kerberos为此设计了一个精巧的方法
a.KDC生成两把一样的密钥Kclt-KDC,作为以后账户A和KDC之间互相认证之用,这样就省去了调出账号A的密码和hash等工作。按理说其中一把Kclt-KDC要发给账户A保管,另一把由KDC自己保管。但是保管密钥对忙碌的KDC来说也是一个负担,所以它决定委托给账户A保管,以后账号A每次需要KDC的时候,再把这密钥还回来。这个办法听上去不太靠谱,万一有个假冒的账户A交回来一把假密钥怎么办?为了避免这个问题,KDC把自己的密码hash成Kkdc,然后用它加密那把委托给A的密钥。Kerberos里把这个委托的密钥称为TGT(Ticket Granting Ticket),可以用下面的公式来表示
TGT = {账户A相关信息,Kclt-kdc}Kkdc
有了这个委托保存的机制,KDC只需记得自己的Kkdc,就能解开委托给所有账号的TGT,从而获得于该账号之间的密钥。通过这个机制,KDC的工作负担就大大降低了
总结下来,KDC回复给账户A的AS_REP应包含以下信息:
AS_REP = TGT,{Kclt-kdc,时间戳,随机字符串}Kclt
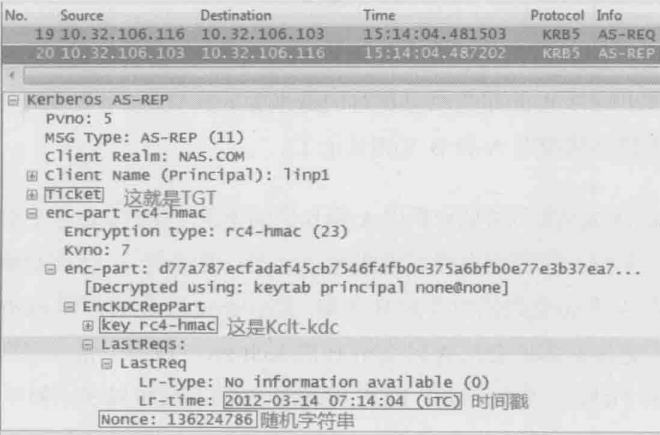
b.账户A收到AS_REP之后利用Kclt解密“{Kclt-kdc,时间戳,随机字符串}”。通过解开来的随机字符串和时间戳来确定KDC的真实性,然后把Kclt-kdc和TGT保存起来备用
第二步,账号请KDC帮忙认证资源B
1.首先TGT是肯定要交还给KDC的,其次还有账户A的相关信息、当前时间戳,以及要访问的资源B的信息(见下图)。这个请求在Kerberos中称为TGS-REQ,可以用下面的公式表示
TGS-REQ = TGT,{账户A相关信息,时间戳}Kclt-kdc,“资源B相关信息”
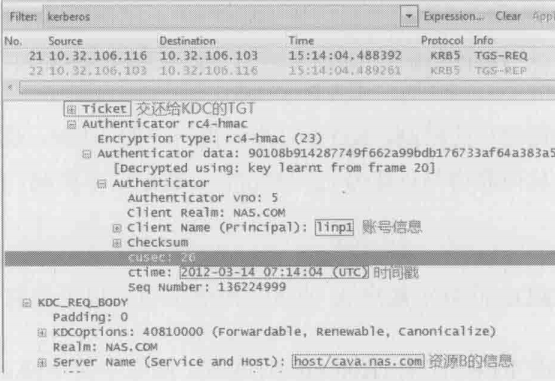
2.KDC收到TGS-REQ之后,先用Kkdc解密TGT得到Kclt-kdc,再用Kclt-kdc解密出账号A的相关信息和时间戳来验证其身份。一旦认定账号A为真,就要想办法帮助A和B互相认证了
3.KDC生成两把同样的密钥供A和B之间使用,我们就称这个密钥为Kclt-srv吧。其中一把密钥直接交给账号A,另一把委托A转交给资源B。为了确保A不会受到假的资源B所骗,Kerberos把B的密码hash成Ksrv,然后用它加密那把委托A转交给B的Kclt-srv,称为一张只有真正的B能解密的Ticket。总结起来,KDC给账号A的回复可以表示如下
Ticket = {账号A的信息,Kclt-srv}Ksrv
TGS_REP = {Kclt-srv}Kclt-kdc,Ticket
这里的“账号A的信息”可不仅仅包括名字,连A所在的Domain Groups都包含在里面。所以如果A属于很多个groups,TGS_REP包会很大
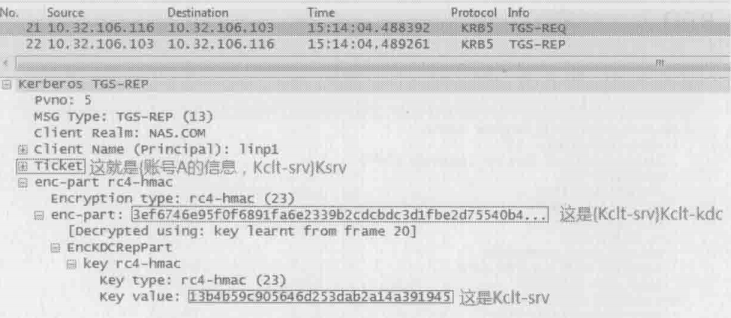
4.账号A收到TGS_REP之后,先用Kclt-kdc解开{Kclt-srv}Kclt-kdc,从而得到Kclt-srv。Ticket留着发给资源B。接下来如果需要多次访问资源B,都可以使用同一个Ticket,而不需要每次都向KDC申请,这也大大降低了KDC的负担
第三步,账号A和资源B互相认证
1.账号A给资源B发送“{账号A的信息,时间戳}Kclt-srv”以及上一步收到的Ticket,这个请求称为AP_REQ
AP_REQ = “{账号A的信息,时间戳}Kclt-srv”,Ticket
2.如果资源B是假的,它是解不开Ticket的。如果资源B是真的,它可以用自己的密码生成Ksrv来解开Ticket,从而得到Kclt-srv。有了Kclt-srv就可以解开”{账号A的信息,时间戳}Kclt-srv”部分。这样资源B就可以确定账号A为真,然后回复AP_REP来证明自己也是真的
AP_REP = {时间戳}Kclt-srv
3.账号A利用Kclt-srv来解密AP_REP,再通过得到的时间戳来判断对方是否为真
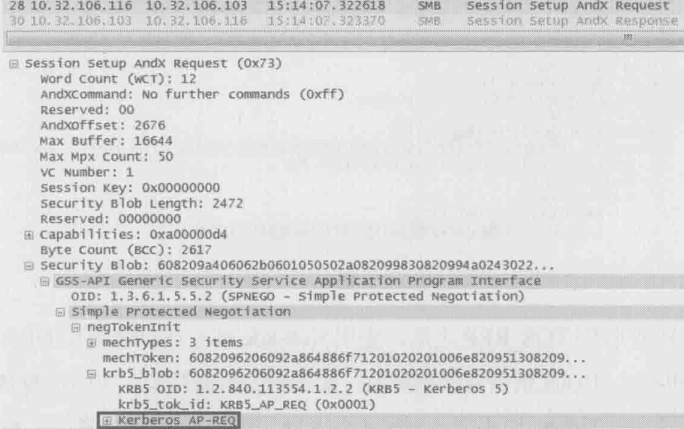
第三步是抓不到网络包的,因为这个实验过程是用户linpl登录windows服务器CAVA,第三步没有发生在网络上。假如接下来用户linpl访问CAVA之外的其他资源,比如访问网络共享,我们就能在Session Setup里找到AP_REQ和AP_REP了。如下图所示,作者在Session Setup AndX Request包中点开Security Blob,就把AP_REQ显示出来了
下图是整个认证过程的流程图
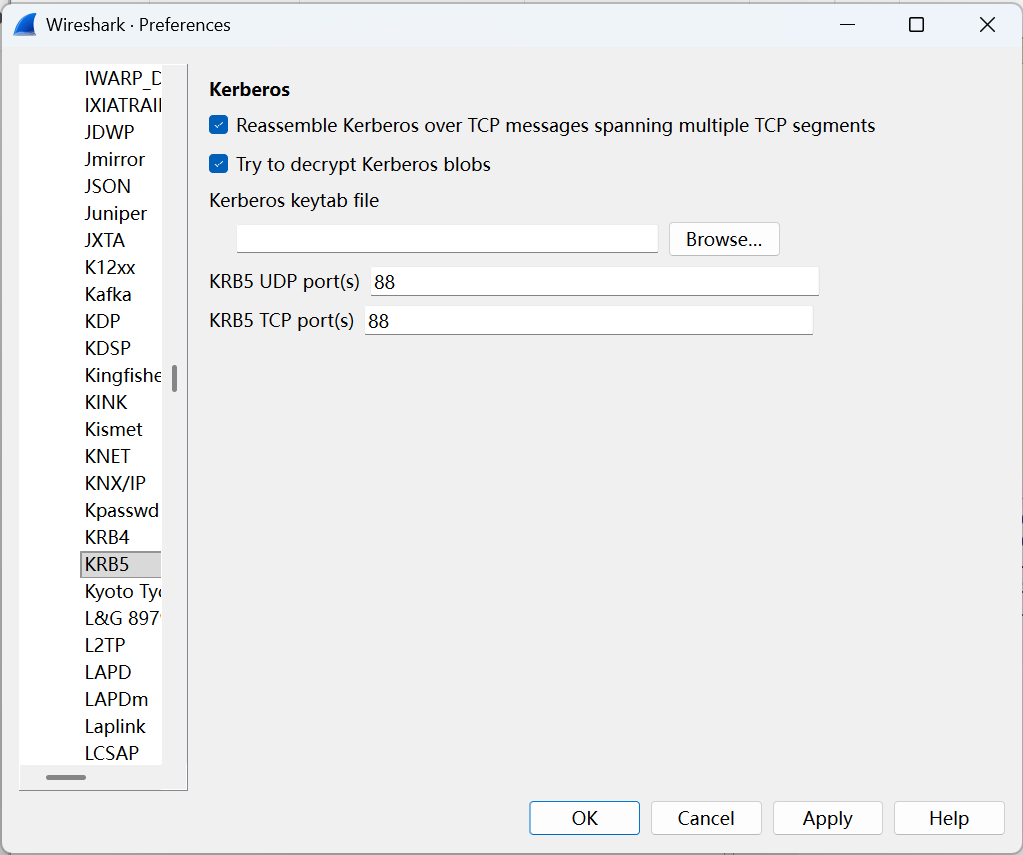
当你完全理解Kerberos之后,可能会意识到一个问题:不对啊,那么多加密信息都被Wireshark显示出来了,还有什么安全可言?其实作者使用linpl的密码生成了一个keytab文件,再用它来解密的。具体操作如下
1.参照Wireshark的官方说明生成keytab文件,步骤请参考http://wiki.wireshark.org/Kerberos
2.把这个文件和网络包放到同一个目录里
3.打开Wireshark的Edit–>Preferences–>Protocols–>KRB5菜单。在下图所示的窗口勾上两个选项,然后输入keytab文件的名字
4.打开网络包,就能看到解密后的内容了
Kerberos相关案例
案例1:某客户可以用“\<IP 地址>”访问某文件服务器,但用了”\<域名>“则不能访问
用了Wireshark抓包才知道,客户端用IP访问时用了NTLM作身份验证,而用域名访问时则用了Kerberos。由于两种验证方法机制不同,所以结果也不一样。比如当客户端和服务器的时间没有同步时,Kerberos会认为该访问时重放攻击而拒绝访问,但NTLM不会
案例2:一个域账号明明被加到某个组里,该组也被赋予访问文件夹的权限,但是该账号就是访问不了这个文件夹
用Wireshark解密了AP_REQ之后,并没有看到那个组。很可能是用户登录(获得包含组信息的Ticket)之后,才被加到那个组里的。让该用户注销后再登录,获得新Tickst就好了
案例3:某台客户端加入域失败,查了很久都没找到原因
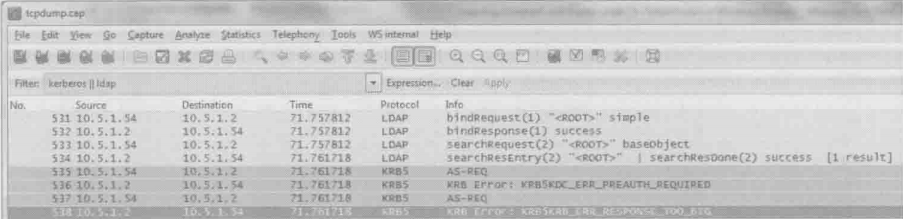
用了Wireshark之后,在包里发现”KRB5KRB_ERR_RESPONSE_TOO_BIG“的错误信息(见下图)。利用该报错很快就从微软的网站上找到了解决方案
TCP/IP的故事
现在人们说到TCP/IP时,指的已经不是TCP和IP两个协议,而是包括了Application Layer、Transport Layer、Internet Layer和Network Layer的四层模型。
令人费解的是,现在的大学课程还在介绍OSI七层模型。它和TCP/IP模型的对应安兴如下图所示。因为OSI模型的层数太多,很多学生根本理解不了,甚至连顺序都记不住。于是老师们就用”All People Seem To Need Data Processing“来帮助记忆
虽然历史上它得到过官方的大力支持,但是市场明显更青睐TCP/IP四层模型
第三章:举重若轻
”一小时内给你答复“
现场工程师搭建了一台文件服务器来提供NFS共享,可是客户端一直挂载不上,每次尝试都收到同一个报错”access denied by server while mounting“如下图所示

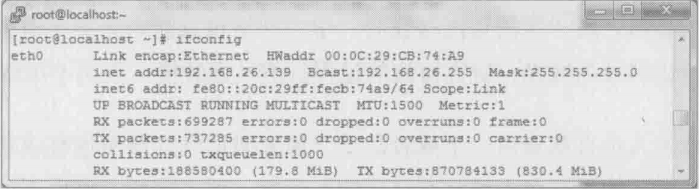
现场工程师很快就把配置信息和网络包传过来了:
服务器IP:
10.32.106.77
NFS共享的访问控制:
/paddynmfs 192.168.26.139(rw)
##只允许192.168.26.139读写,其他客户端不能挂载
客户端IP:
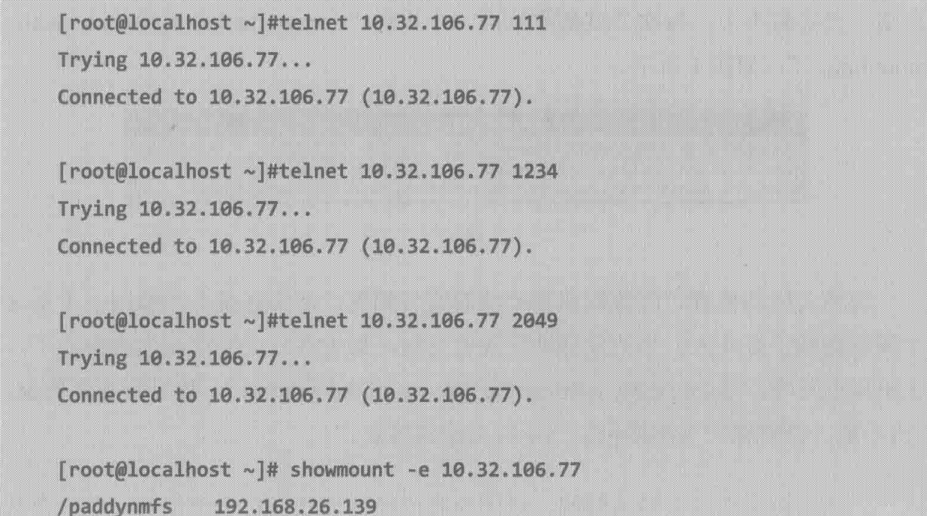
现场工程师的排查过程如下所示:
作为”碰运气“步骤,现场工程师把客户端和服务器都重启过了,但结果还是一样
作者仔细检查完以上信息,结论和现场工程师一样——服务器和客户端的配置都没问题。而且从排查过程还可以知道:
从telnet的输出结果可见portmap(111)、mount(1234)、已经NFS(2049)进程所对应的端口都是可达的,这说明网络是通的,没有防火墙之类的设备拦截了挂载请求
从showmount的结果可以看到,挂载时指定的共享路径也是正确的
作者用Wireshark打开服务器上抓到的包,然后用192.168.26.139过滤了以下,如下图所示
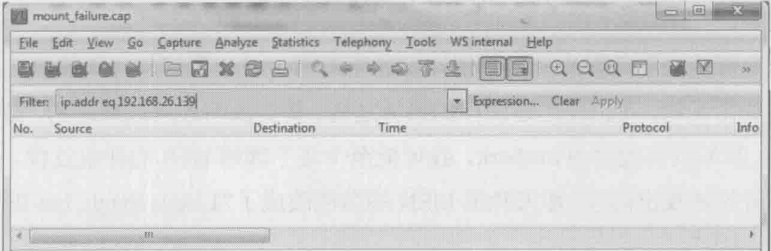
结果竟然是空的,作者又换了一个过滤表达式,把所有mount包显示出来,结果如下图所示
 从上图中可以看出,客户端10.32.200.45发送了mount请求,但被服务器10.32.106.77拒绝了,这倒符合”Access Denied“的症状。但是客户端的IP不应该是192.168.26.139吗,怎么变成10.32.200.45了?这时突然恍然大悟:两个网络之间估计存在NAT(Network Address Translation),当客户端发出的请求经过NAT设备时,SourceIP 被改掉了(下图显示了这个过程)
从上图中可以看出,客户端10.32.200.45发送了mount请求,但被服务器10.32.106.77拒绝了,这倒符合”Access Denied“的症状。但是客户端的IP不应该是192.168.26.139吗,怎么变成10.32.200.45了?这时突然恍然大悟:两个网络之间估计存在NAT(Network Address Translation),当客户端发出的请求经过NAT设备时,SourceIP 被改掉了(下图显示了这个过程)

由于服务器上的访问控制只允许192.168.26.139访问,所以来自10.32.200.45的挂载请求自然被拒绝了
午夜铃声
作者用Wireshark粗略一看,发现很多包发生了重传(Retransmission),而且还有大量乱序(Out-Of-Order)。下面是Wireshark的分析结果
重传:
乱序:
作者的第一反应便是乱序导致了重传,从而影响了性能
在正常情况下,网络包到达接受方时的Seq号应该是顺序的,比如在每个包长度为1460的情况下,Seq号可能时这样的:1460,2920,4380……因此接收方能算出下一个包的Seq号应该是什么。比如4380+1460=5840,加入收到的不是5480,接收方就知道包序乱了。这是它应该回复一个包给发送方,说”我要的是5840(即Ack 5840)“
而对于发送方来说,持续收到”我要的是5840“可能意味着5840跑到其他包后面了,也可能意味着5840已经丢失。RFC里这样定义:如果发送方收到3个及以上重复的”我要的是X“,即可认为包X已经丢失,应当启动快速重传。下图演示了这个过程

最终接收方会收到两个一样的Seq=5480,即乱序了的原始包,还有一个重传包。其中第二个到达的包相当于浪费了
作者在Wireshark上随机跳出几个重传包,发现方向都是从Isilon(服务器)到windows的,恰好符合读性能差的症状。作者于是草拟了一个计划
1.把Isilon和windows客户端连到同一台空闲的交换机,尽量排除网络设备的影响
2.Isilon和其他服务器一样,应该有类似NIC teaming的功能。根据作者的经验,乱序有时候就是由teaming导致的,可以尝试关闭。作者还碰到过Large Segment Offload(LSO)导致的乱序,也是一个考虑因素
注:
NIC teaming(Network Interface Card teaming,网络接口卡组合,也称链路聚合)的核心作用是将多个物理网卡(NICs)组合成一个逻辑网卡从而实现高可用性、带宽聚合和负载均衡
LSO(Large Segment Offload,大段卸载)是一种网络性能优化技术,主要用于减轻主机CPU在处理大量TCP数据发送时的负担
3.实在不行,就在Isilon和windows上同时抓包,两者一对比就能发现很多问题
其他的几位工程师这几天做过很多方面的尝试,包括作者计划的第一步,但是性能没有任何改变。windows客户端也换过几台,但结果都差不多。目前来看网络设备和客户端都不是瓶颈,估计原因就出在Isilon上了。也许明天关闭Isilon上的NIC teaming 和LSO问题就解决了吧?
作者终于在Isilon上找到LargeSegment Offload和NIC teaming的开关,并满怀希望地关闭了它们。当启动测试脚本的时候,结果令人大跌眼镜——读性能比之前还差!只能说先抓个包看看吧。这一抓包更是意外,居然看不到乱序的包了!可见之前的猜测没有错,乱序是由NIC teaming 或者LSO导致的。但为什么消除了乱序之后性能没有改善呢?再看看重传率,果然还是很高
到这里只剩下一个解释了——重传并非乱序引起的。作者重新研究昨天拿到的网络包,当作者逐个检查乱序的包时,果然看到了一个很有趣的现象。如下图所示,虽然乱序的包很多,但只是相邻的两个包的颠倒,因此,接收方只放出了1个”我要的是X“,而不会凑满3个以上相同的”我要的是X“来触发重传。这就解释了为什么重传不是由乱序导致的
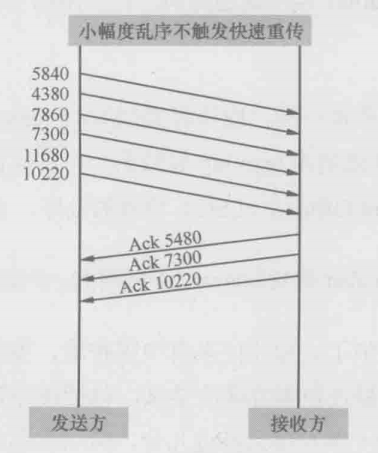
举个更通俗的例子,当序号为1、2、3、4、5、6的一系列包到达接收方时,如果次序乱成了2、1、4、3、6、5,是不会触发快速重传的;但如果乱成2、3、4、5、6、1,就会导致重传
再分析消除乱序后再接收方抓到的网络包,现象就更加有趣了。如下图所示,接收方明明收到了 Seq 20440(Frame No.3),但它竟然发送了四个”Ack 20440“给发送方,从而促使发送方重传了Seq 20440(Frame No.13)
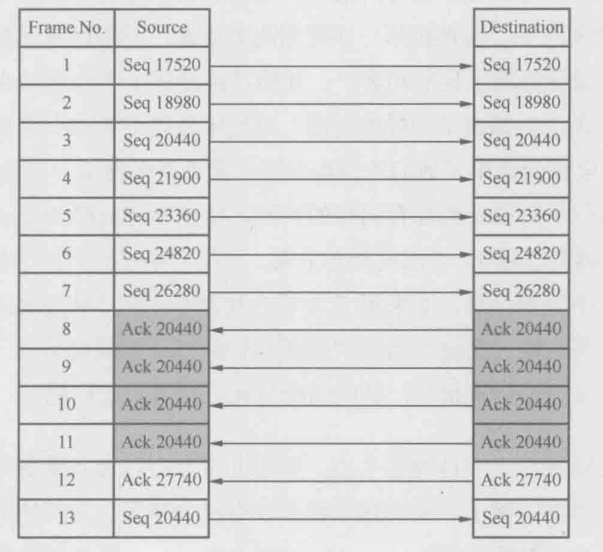
这个现象实在太”不科学“了。按理说这个包是在接收方抓的,Wireshark上也已经显示了”Seq 20440“,就意味着接收方已经收到,为什么还会连发四个Dup Ack呢?
作者回忆起RFC中关于快速重传的描述:”当接收方收到比期望值大的Seq时,就要向发送方Ack 它期望的Seq值……“根据这个理论,难道接收方在收发票20440之前,已经收到了21900、23360、24820和26280这4个包?从Wireshark里看20440明明是排在这4个包前面的
会不会是20440本身的checksum有问题,被接收方抛弃了呢?再看看上图中最后两个包,重传的Seq 20440(Frame No.13)到达接收方之前,接收方已经回复了”Ack 27740“(Frame No.12),这表明接收方收到了27740之前的所有包,包括20440。也就是说,20440真的是被移到26280后面了,而不是因为checksum无效被抛弃
注:
checksum(校验和)是一种用于检测数据在传输或存储过程中是否发生错误的简单而广泛使用的完整性验证机制
那是什么因素导致接收方把20440移到26280后面呢?目前不得而知,但TCP/IP是分层协作的,也许是网络层把包交给TCP层时打乱了。
分析到这里,可以肯定重传的根本原因就是接收方自身地乱序,而网络设备和Isilon都被冤枉了。这不但颠覆了作者之前地分析结果,而且难以说服现场工程师和客户。还好最后查到一个重要信息,原来那7台客户端都是用一张ghost盘安装的,客户终于让步,答应明天新装7台客户端供作者测试。第二天作者又一次启动测试脚本,这一次每台的读性能都能达到100MB/s,大大超过了客户80MB/s的预期
深藏功与名
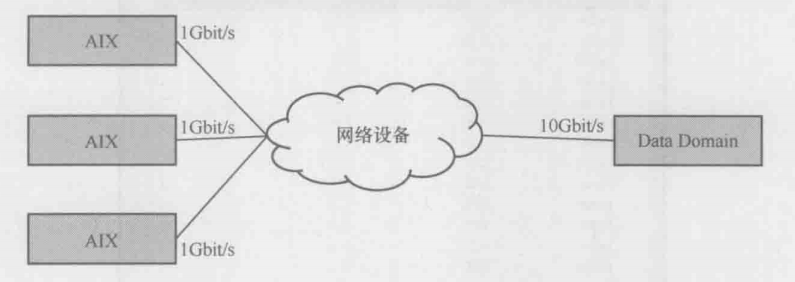
大概了解的症状是多台AIX同时往Data Domain读写数据(如下图所示)。写的时候性能很好,能超过90MB/s;但读的时候性能却很差,在20MB以下
注:
AIX(Advanced Interactive Executive,高级交互性执行程序)是由IBM(国际商业机器公司)开发的一种专有Unix操作系统,主要用于其Power Systems 服务器平台
 z
z
1.一般存储设备都是读比写快,Data Domain应该也不例外。目前的现象是读比写慢得多,所以根本原因应该不在Data Domain本身
2.网络很值得怀疑。一般存储端的带宽大,客户端的带宽小。读文件时数据从大带宽进入小带宽,就如同大河水流入小河,有可能会溢出(表现在网络上就是拥塞)而导致性能问题。写文件时方向相反,所以拥塞概率低,性能就会好一些,正好符合这个案例的症状
3.只要在两端各抓一个包,就能证实作者的猜测
用Wireshark打开一看,果然发现了好多重传(如下图所示)。重传对性能的影响是极大的,即便是0.5%的比例也会使性能大幅度下降
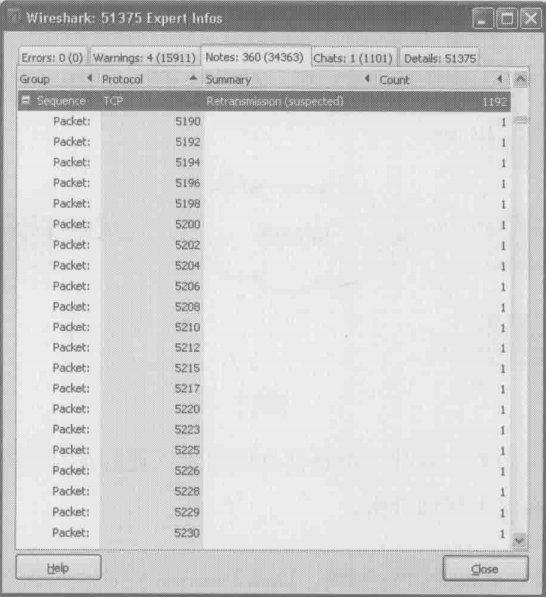
作者随机看了几个重传包,发现方向都是从Data Domain到AIX的。说明这些包从Data Domain出来之后,在路上丢失了,最终没有到达AIX。Data Domain因为一直没有等到AIX的确认包,所以只能选择重传
这就意味着作者之前的推测是正确的,网络上存在瓶颈。客户也确认AIX端的带宽只有存储端的1/10,是可能有问题。不过由于网络项目已经实施完毕,无法变动,所以只能从Data Domain和AIX上想办法
方案1:把Data Domain的发送窗口强制成较小的值,这样每次发出去的数据量就少一些,拥塞的概率也减小了。发的慢当然对性能有影响,但由于避免了丢包,所以总性能反而有所提升。该方案的缺点是限制了Data Domain给所有网络设备发送数据的速度,不仅是针对AIX
方案2:把AIX的接收窗口强制成较小的值。这样Data Domain给AIX传数据时的发送窗口就被限制了,而且给其他客户端发数据时不受影响。但该方案的缺点是限制AIX从所有网络设备接收数据的速度,不只是针对Data Domain
以上两个方案都需要选定一个较小的窗口值,这个值要怎么算出来呢?下图是一个丢包的例子,发送方一口气发出6个包,但其中最后一个丢失了,最后导致了超时重传
从上图中可以估算出丢包时的拥塞点大约为前5个包所携带的字节数。只要按这个方法随机找出多个拥塞点,就大概能选定合适的窗口值了
方案3:上上张图中的Wireshark截图显示重传的包为5190、5192、5294……5230(20个),而且这些重传包都是连续的
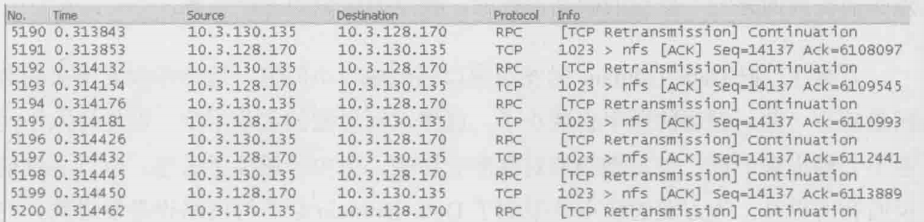
但是当作者检查接收方的网络包时,发现其实只有5190的原始包时真正丢失的,其他的包都到达了接收方,所以没必要重传。那为什么发送方要重传这么多呢?这是因为发送方发现5190的原始包丢失后,无法确定后续的其他包是否也丢了,只好选择全部重传。而接收方虽然知道丢了哪些包,却没有任何机制可以告知发送方。这个问题其实在1996年的RFC2018中就已经给出了解决方案,它就是Selective Acknowledgment,简称SACK。在接收方和发送方都启用SACK的情况下,接收方可以告诉发送方”我没收到的只是5190的原始包,但是我收到了其他的。“因此发送方只需重传5190即可。在启用了SACK的网络包中,我们能在Dup Ack包里看到这些信息。下图是在一个启用SACK的环境中抓的包,最底部就是SACK信息
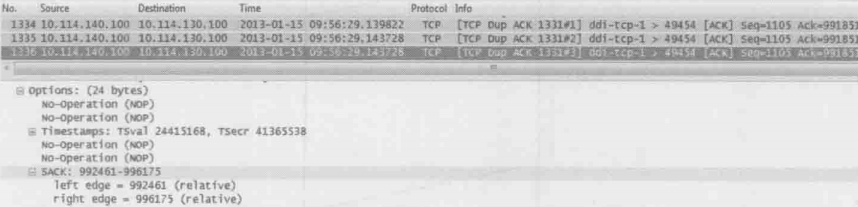
把上图中的”Ack=991851“和”SACK=992461-996175“两个信息综合起来,发送方就知道991851992460的包没有收到,而后面的992461996175的包反而已经收到了
因为本案例中存在大量不必要的重传,而且DupAck包中也没有SACK信息,已经足以说明SACK没有启用。作者决定先不限制发送窗口,把SACK打开再说。是否启用SACK是在TCP三次握手时协商决定的,如下图中方框内的参数所示。只要双方中有一方没有发”SACK_PERM=1“,那该连接建立之后就不会用到SACK

作者分别检查了Data Domain 和 AIX,果然发现AIX上默认关闭了SACK。于是客户在AIX上运行了”no -p -o sack=1“命令,读性能立即就飙升到90MB/s以上,远远超过项目需求。有了这个结果,也不用再考虑方案1和方案2了,毕竟都有副作用
棋逢对手
一位澳洲用户的文件服务器同时为多台Linux应用服务器提供NFS访问。系统再实施阶段非常顺利,于是便择日上线了。不幸的是到了生产环境中,应用服务器访问文件时偶尔会卡一下,而且这症状的出现是不定时的、稍纵即逝的。谁也不知道接下来是什么时候,发生再哪台应用服务器上。经验丰富的系统管理员已经检查过应用服务器、文件服务器和网络设备的所有日志,可惜没有发现有价值的信息
作者是这样分析该症状的
1.访问文件时感到卡,可能是文件服务器负载过重,导致了响应慢;也可能是网络拥塞,发生了连续多次的重传
2.虽然无法预测问题发生的事件,但如果在业务繁忙是抓个网络包,应该多少能看到一些端倪
可是管理员却说:”存储上的网络包我已经抓过了,分析下来一点问题都没有。“
用Wireshark打开网络包之后,作者习惯性地试了”性能问题三板斧“
1.单机Statictics–>Capture File Properties。从Avg.MBit/sec看到,那段时间的流量不高,所以该存储的负担似乎并不重
2.单机Statistics–>Service Response Time –>ONC-RPC –>Program:NFS Version:3 –>Create Stat,可以看到各项操作的Service Response Time都不错(见下图),这进一步说明该存储并没有过载
3.单机Analyze –>Expert Information,从Error和Warning里都没有看到报错,这说明网络没有问题(见下图)假如有重传、乱序之类的现象,应该能在这个窗口里看到
这个系统看起来如此健康,完全不像是会卡的样子,接下来该怎么处理?看来一定要在出问题的时刻抓到包,除此之外,别无他途了
好消息接踵而至,几天后网络包真的抓到了,还记录了出问题的时间点。作者满怀希望地又试了三板斧,预感这次一定能看到某些迹象。没想到一番忙活之后,竟然和之前地分析结果一摸一样——什么迹象都没看到
作者根据问题发生地时间点过滤出前后两秒钟地所有包,然后逐个检查。这下果然看到一个意想不到的包:如下图中的包号440354所示,NFS服务器172.16.2.80给客户端172.16.2.102发了一个Portmap请求,咨询其NLM进程的端口号。更异常的是这个请求竟然没有得到回复

NLM是Network Lock Manager的简称。客户端用它来锁定服务器上的文件,从而避免和其他客户端发生访问冲突。一般都是由客户端查询服务器的NLM端口,这种反方向的状况还是第一次见到。这个Portmap请求出现在这里虽然有点突兀,不过似乎可以忽略,因为作者想不出它根访问文件卡有什么联系
遍历了所有包之后,仍然一无所获,作者还是决定从头再来,这次要更细致地分析每一个包。作者收集了一些资料,重温了一遍NLM的工作原理,然后把NLM工作过程总结如下
1.客户端甲→NLM_LOCK_MSG request→NFS服务器(甲尝试锁定一个文件)
** 客户端甲←NLM_LOCK_RES granted←NFS服务器(服务器同意了这个锁定)**
2.客户端乙→NLM_LOCK_MSG request→NFS服务器(乙尝试锁定同一个文件)
** 客户端乙←NLM_LOCK_RES blocked←NFS服务器(因为该文件已经被甲锁定,所以服务器让乙先等着)**
3.客户端甲→NLM_UNLOCK_MSG request→NFS服务器(甲尝试释放锁)
** 客户端甲←NLM_UNLOCK_RES granted←NFS服务器(服务器同意释放)**
4.客户端乙←NLM_GRANTED_MSG request←NFS服务器(服务器主动把锁给了乙)
** 客户端乙→NLM_GRANTED_RES accept→NFS服务器(乙接受了)**
Wireshark里看到的那个Portmap请求,发生在上面的哪个步骤呢?应该在第三步和第四步之间。就在找到答案的一刹那,作者恍然大悟,一下子知道问题出在哪了
1.第三步之后,服务器要通过Portmap查询乙的NLM端口号(也就是那个诡异的包),得到回复后才能进入第四步
2.假如查询端口号失败,则第四步无法进行,也就意味着服务器没有办法把锁给乙
3.由于乙得不到锁,所以只能继续等到超时为止。这对于程序来说,就是卡住了
4.该问题只发生在多个客户端同时访问同一文件的情况下,所以表现为偶发症状
5.乙没有响应Portmap查询,很可能是包被防火墙拦截了
学无止尽
tshark的优势
当你用Wireshark解决了一个又一个难题时,再谦虚的人也会自信心膨胀,一位没有什么问题是解决不了的,可以这只是错觉,因为Wireshark的确有它的应用极限
作者之前碰到过这样一个问题:接收方不时回复”TCP Window=0“,导致发送方只能停下来等待。整个传输过程的Sequence Number曲线类似于下图所示,其中水平部分表明接收方当时正在发”TCP Window=0“
为了给客户出一份专业的分析报告,作者需要统计出”TCP Window=0“所导致的停止总共有多少毫秒。通过上图的很坐标来统计显然不够精确,所以作者不得不把所有的问题包过滤出来,逐段统计停滞的时间。像上图这样只有两端停滞时间的情况还好,碰到有几十段的时候就很费时了
为什么要人工地去做如此简单地重复劳动呢?这明显更适合由程序来完成,凡是Wireshark没有提供这项功能。但作者只需要在tshark里运行以下命令,该脚本就可以把总停滞时间算出来了

上面用到的tshark命令就相当于Wireshark的命令行版本2.和图形界面相比,命令行有一些先天的优势
1.如上例所示,命令行的输出可以通过awk之类的方式直接处理,这是图形界面无法实现的。有些高手之所以说tshark的功能比Wireshark强大,也大多处于这个原因
2.编辑命令虽然费时,但是编辑好之后可以反复使用,甚至可以写成一个软件。比如作者经常需要进行性能调优,那就可以写一段程序来完成多次提到过的三板斧(Capture File Properties,Response Time和Expert Information)。拿到一个性能相关的包之后,直接运行该程序就可以得到三板斧结果,这比用Wireshark快多了
3.tshark输出的分析文本大多可以直接写入分析报告中,而Wireshark生成不了这样的报告。比如说,我想统计每一秒钟里CIFS操作的Service Response Time,那只要执行以下命令就可以了,如下图所示

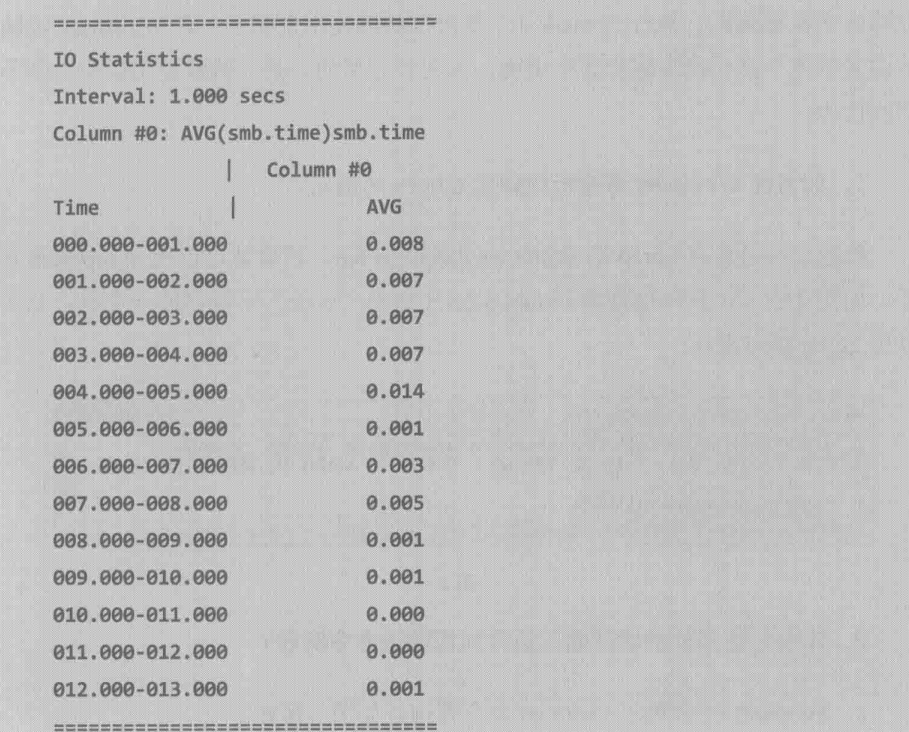
这个结果导入Excel,友可以生成各种报表
4.和其他软件一样,命令行往往比图形化界面快得多。比如现在有一个很大的包需要用IP 192.168.1.134过滤,用Wireshark操作的话先得打开包,再用ip.addr==192.168.1.134过滤,最后保存结果。这三个步骤都很费时,但是tshark用下面一条命令就可以完成了
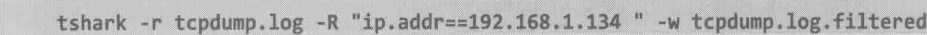
学无止尽,当你掌握了足够多的经验时,就可以完全忽略Wireshark的友好界面,转而追求更高效,也更复杂的tshrak
tshark的技巧
tshark的入门并不难。在安装好tshark的操作系统上(安装Wireshark的时候也默认安装tshark)。执行”tshark-h“就可以阅读使用说明了。本文要分享的,是一些从使用说明上学不到的技巧
1.如何在Windows命令行中搜索tshark的输出?
建议安装含有qgrep的Windows Resource Kit,然后就可以用qgrep来搜索了
我希望搜索mount.pcap中含有”code“字符串的一个包,就可以用qgrep找出来

2.本书介绍过的性能问题三板斧如何通过命令实现?
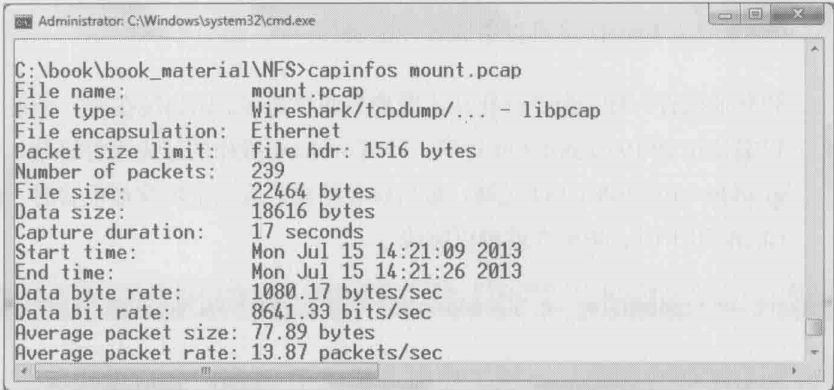
a.Summary(Capture File Properties)可以通过capinfos命令查询,如下图所示
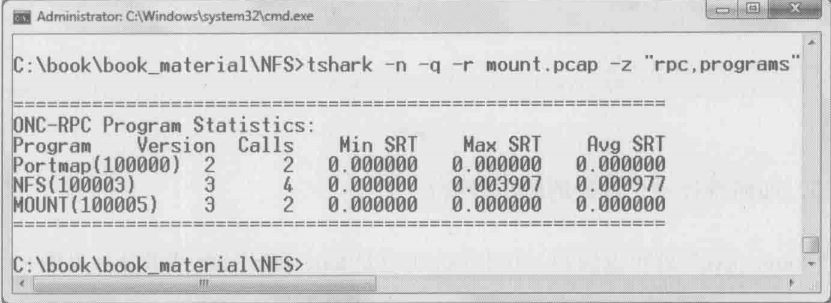
b.获取Service Response Time则要视不同协议而定,比如NFS协议可以用下图中的命令
CIFS协议只要把上图中双引号中的内容改为”smb,rtt“即可
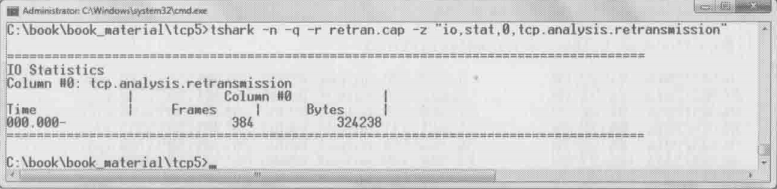
c.重传状况要用到 tcp.analysis.retransmission命令,注意下图中这384个frames包括了超时重传和快速重传两种情况
d.乱序状况则只要把”retransmission“改成”out_of_order“

3.如何统计一个包里的所有对话?
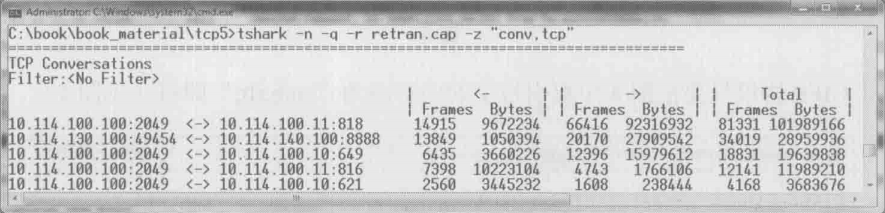
”conv,xxx“就可以做到,其中xxx可以是tcp、udp、eth或者ip(见下图)
4.如果一个包大得连tshark都无法打开,有没有办法切分成多个?
可以使用editcap命令来做到。作者常用”editcap
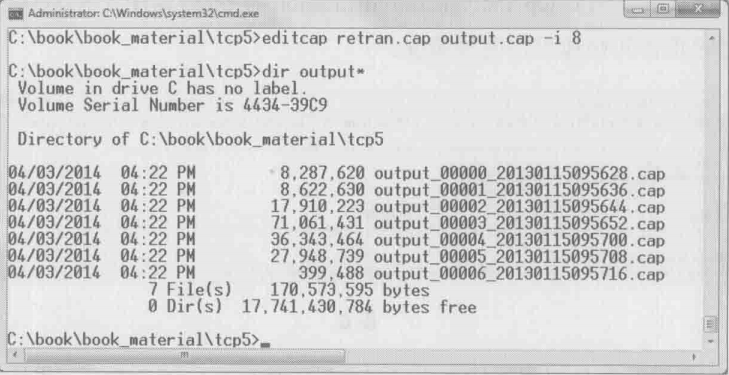
除了这里介绍的这些,tshark下的网络分析技巧还有很多,值得每位工程师长期学习。如果学习过程中遇到任何问题,建议查询Wireshark的官方说明,地址为http://www.wireshark.org/docs/man-pages/tshark.html
一个技术男的自白
摸了一个多月也总算是完结撒花啦☆: .。. o(≧▽≦)o .。.:☆,这篇文章纯手打,如果后续有读者发现错别字也请见谅(前提是有读者能看到这里的情况下T-T)
原著到这一章作者通过自述一些Wireshark以外的事算是给这本书做了一个结尾。我作为一个纯理科生(现在有待成为理工男),我认为这个标题其实也适用于我
正好基于这本书对于Wireshark的入门学习算是完结了,借此我也想抒发以下自己在阅读和学习这本书时产生的感想
首先,这篇文章大部分内容是基于作者的原话,还有很多电脑实操的图片也是直接从书上照搬下来的,只有少部分内容是个人在阅读时认为作者没有科普到位的补充了说明,还对章节进行了更细致的划分和重点加粗提示,有人会觉得那我这篇文章不就是纯粹地复制粘贴吗,有什么意义呢?
自高中起,我就特别喜爱记笔记,高一的时候比较空闲,我每天都会把写完作业剩余地两个多小时用来记化学笔记,其内容本质上无异于这篇文章——不过是把老师上课的PPT以手写的形式再在笔记本上呈现一遍。但我认为这就是属于我的学习方式,通过一遍遍的书写能够让我在无形中形成记忆(这或许也就是常说的笨鸟先飞、勤能补拙吧),学习Wireshark的过程也是一样,一连串的协议对于初见的我来说就如天书,通过这种方式能让我认真完成阅读并且对于各个书中提及的协议有一个更深的理解。以上是我个人学习习惯的原因,从Wireshark来看,书中提及的知识点太过专业化,更何况作者是一名优秀的工程师,很多的概念都是我正常无法触及到的内容。因此,我觉得,以我现在的水平去提炼、去概括,甚至于是纠正作者的笔误,是无法做到的事;并且本书的知识高度凝练,作者的表达在我看来是对于初学者以及以后的我再来回顾的最佳文本。因此,我选择保留作者原意
其次,这本书的内容超越了我原本阅读前对它的预想。我原以为这本书只是如同工具书一般死板的列出每个公式和适用环境,实则不然,作者以其幽默以及生活化的描述将Wireshark和网络分析的基础——协议展现给每位读者。你完全不用把这本书当作一个难啃的理工类工具书,其实静下心来把里面的案件当作故事看也饶有趣味
最后,这本书可以说是作为我深入信安领域的引路人,我从中终于明白了”三次握手“和”四次挥手“是什么,还有经典的TCP/IP模型。文中最让我感兴趣的是”无懈可击的Kerberos“,作者以他独特的方式拆解了网络上进行双向认证的过程。 虽然REQ,REP之类的参数名看的眼花缭乱,但是作者也让我体会到了密码学的趣味,其认证过程一步衔接下一步,没有任何多余,极具逻辑性和数学的美感,这也让我有了读完这本书后继续去钻研密码学的兴趣
身为一名刚进入大学的大一学生,说什么编写程序都为时太早,很喜欢作者上一个小章节的标题:学无止尽,为了去达到比赛的目标我还需要学习的太多。路漫漫其修远兮,吾将上下而求索。希望今后再回头看这篇文章时我依然能保持热情钻研我所想钻研的,学习我想学习的
2026.1.7